Un aspect important de Apprentissage automatique est l’évaluation du modèle. Vous devez disposer d'un mécanisme pour évaluer votre modèle. C’est là que ces mesures de performances entrent en jeu : elles nous donnent une idée de la qualité d’un modèle. Si vous connaissez certaines des bases de Apprentissage automatique alors vous devez avoir rencontré certaines de ces métriques, comme l'exactitude, la précision, le rappel, l'auc-roc, etc., qui sont généralement utilisées pour les tâches de classification. Dans cet article, nous explorerons en profondeur l’une de ces mesures, à savoir la courbe AUC-ROC.
Table des matières
- Qu'est-ce que la courbe AUC-ROC ?
- Termes clés utilisés dans les courbes AUC et ROC
- Relation entre la sensibilité, la spécificité, le FPR et le seuil.
- Comment fonctionne l’AUC-ROC ?
- Quand devrions-nous utiliser la métrique d’évaluation AUC-ROC ?
- Spéculer les performances du modèle
- Comprendre la courbe AUC-ROC
- Implémentation à l'aide de deux modèles différents
- Comment utiliser ROC-AUC pour un modèle multi-classes ?
- FAQ sur la courbe AUC ROC dans l’apprentissage automatique
Qu'est-ce que la courbe AUC-ROC ?
La courbe AUC-ROC, ou courbe Area Under the Receiver Operating Characteristic, est une représentation graphique des performances d'un modèle de classification binaire à différents seuils de classification. Il est couramment utilisé en apprentissage automatique pour évaluer la capacité d'un modèle à distinguer deux classes, généralement la classe positive (par exemple, la présence d'une maladie) et la classe négative (par exemple, l'absence d'une maladie).
Comprenons d’abord la signification des deux termes ROC et AUC .
- ROC : Caractéristiques de fonctionnement du récepteur
- AUC : Aire sous la courbe
Courbe des caractéristiques de fonctionnement du récepteur (ROC)
ROC signifie Receiver Operating Characteristics, et la courbe ROC est la représentation graphique de l'efficacité du modèle de classification binaire. Il représente le taux de vrais positifs (TPR) par rapport au taux de faux positifs (FPR) à différents seuils de classification.
Aire sous la courbe (AUC) Courbe :
AUC signifie Area Under the Curve, et la courbe AUC représente l'aire sous la courbe ROC. Il mesure les performances globales du modèle de classification binaire. Comme TPR et FPR sont compris entre 0 et 1, la zone se situera toujours entre 0 et 1, et une valeur plus élevée de l'AUC dénote de meilleures performances du modèle. Notre objectif principal est de maximiser cette zone afin d'avoir le TPR le plus élevé et le FPR le plus bas au seuil donné. L'AUC mesure la probabilité que le modèle attribue à une instance positive choisie au hasard une probabilité prédite plus élevée par rapport à une instance négative choisie au hasard.
Il représente le probabilité avec lequel notre modèle peut distinguer les deux classes présentes dans notre cible.
Métrique d'évaluation de la classification ROC-AUC
Termes clés utilisés dans les courbes AUC et ROC
1. TPR et FPR
Il s’agit de la définition la plus courante que vous auriez rencontrée lorsque vous rechercheriez AUC-ROC sur Google. Fondamentalement, la courbe ROC est un graphique qui montre les performances d'un modèle de classification à tous les seuils possibles (le seuil est une valeur particulière au-delà de laquelle vous dites qu'un point appartient à une classe particulière). La courbe est tracée entre deux paramètres
- TPR – Taux de vrai positif
- FPR – Taux de faux positifs
Avant de comprendre, TPR et FPR regardons rapidement les matrice de confusion .
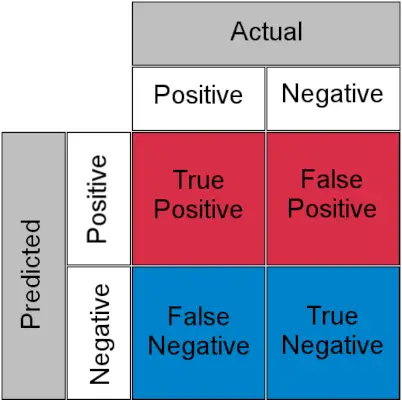
Matrice de confusion pour une tâche de classification
- Vrai positif : Réel positif et prédit comme positif
- Vrai négatif : Réel négatif et prédit comme négatif
- Faux positif (erreur de type I) : Réel négatif mais prédit comme positif
- Faux négatif (erreur de type II) : Réel positif mais prédit comme négatif
En termes simples, vous pouvez appeler un faux positif un fausse alarme et faux négatif a manquer . Voyons maintenant ce que sont TPR et FPR.
2. Sensibilité / Taux de vrais positifs / Rappel
Fondamentalement, TPR/Recall/Sensitivity est le ratio d’exemples positifs correctement identifiés. Il représente la capacité du modèle à identifier correctement les instances positives et est calculé comme suit :

La sensibilité/rappel/TPR mesure la proportion d'instances positives réelles qui sont correctement identifiées par le modèle comme positives.
3. Taux de faux positifs
Le FPR est le ratio d’exemples négatifs mal classés.

4. Spécificité
La spécificité mesure la proportion d'instances négatives réelles qui sont correctement identifiées par le modèle comme négatives. Il représente la capacité du modèle à identifier correctement les instances négatives

Et comme indiqué précédemment, le ROC n'est rien d'autre que le tracé entre TPR et FPR sur tous les seuils possibles et l'AUC est toute la zone située sous cette courbe ROC.
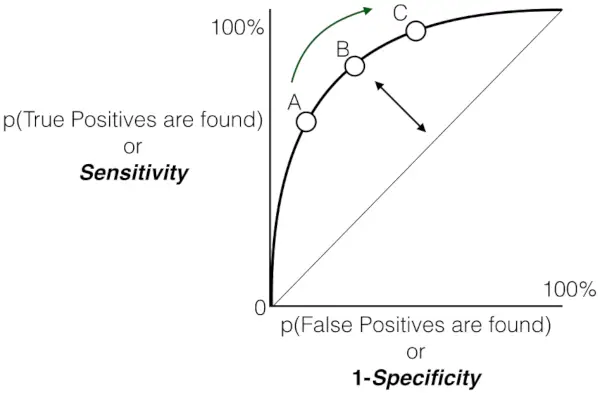
Diagramme de sensibilité par rapport au taux de faux positifs
Relation entre la sensibilité, la spécificité, le FPR et le seuil .
Sensibilité et spécificité :
- Relation inverse: la sensibilité et la spécificité ont une relation inverse. Quand l’un augmente, l’autre tend à diminuer. Cela reflète le compromis inhérent entre les taux véritablement positifs et véritablement négatifs.
- Réglage via le seuil : En ajustant la valeur seuil, nous pouvons contrôler l’équilibre entre sensibilité et spécificité. Des seuils plus bas conduisent à une sensibilité plus élevée (plus de vrais positifs) au détriment de la spécificité (plus de faux positifs). A l’inverse, relever le seuil augmente la spécificité (moins de faux positifs) mais sacrifie la sensibilité (plus de faux négatifs).
Seuil et taux de faux positifs (FPR) :
- Connexion FPR et spécificité : Le taux de faux positifs (FPR) est simplement le complément de la spécificité (FPR = 1 – spécificité). Cela signifie la relation directe entre eux : une spécificité plus élevée se traduit par un FPR plus faible, et vice versa.
- Modifications du FPR avec le TPR : De même, comme vous l’avez observé, le taux de vrais positifs (TPR) et le FPR sont également liés. Une augmentation du TPR (plus de vrais positifs) entraîne généralement une augmentation du FPR (plus de faux positifs). A l’inverse, une baisse du TPR (moins de vrais positifs) entraîne une baisse du FPR (moins de faux positifs)
Comment fonctionne l’AUC-ROC ?
Nous avons examiné l'interprétation géométrique, mais je suppose que cela n'est toujours pas suffisant pour développer l'intuition derrière ce que signifie réellement 0,75 AUC. Examinons maintenant AUC-ROC d'un point de vue probabiliste. Parlons d'abord de ce que fait la CUA et plus tard, nous bâtirons notre compréhension sur cela.
L'AUC mesure dans quelle mesure un modèle est capable de distinguer Des classes.
Une AUC de 0,75 signifierait en fait que disons que nous prenons deux points de données appartenant à des classes distinctes, il y a 75 % de chances que le modèle soit capable de les séparer ou de les classer correctement, c'est-à-dire que le point positif a une probabilité de prédiction plus élevée que le négatif. classe. (en supposant qu'une probabilité de prédiction plus élevée signifie que le point appartiendrait idéalement à la classe positive). Voici un petit exemple pour que les choses soient plus claires.
Indice | Classe | Probabilité |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Ici, nous avons 6 points où P1, P2 et P5 appartiennent à la classe 1 et P3, P4 et P6 appartiennent à la classe 0 et nous correspondons aux probabilités prédites dans la colonne Probabilité, comme nous l'avons dit si nous prenons deux points appartenant à des valeurs distinctes. classes, quelle est la probabilité que le classement du modèle les classe correctement.
Nous prendrons toutes les paires possibles de telle sorte qu'un point appartient à la classe 1 et l'autre à la classe 0, nous aurons un total de 9 paires de ce type ci-dessous sont toutes ces 9 paires possibles.
Paire | est correct |
|---|---|
(P1,P3) | Oui |
(P1,P4) | Oui |
(P1,P6) | Oui |
(P2,P3) | Oui angles adjacents |
(P2,P4) | Oui |
(P2,P6) | Oui |
(P3,P5) | Non |
(P4,P5) | Non |
(P5,P6) | Oui |
Ici, la colonne Correct indique si la paire mentionnée est correctement classée en fonction de la probabilité prédite, c'est-à-dire que le point de classe 1 a une probabilité plus élevée que le point de classe 0, dans 7 de ces 9 paires possibles, la classe 1 est classée supérieure à la classe 0, ou nous pouvons dire qu'il y a 77 % de chances que si vous choisissez une paire de points appartenant à des classes distinctes, le modèle soit capable de les distinguer correctement. Maintenant, je pense que vous pourriez avoir un peu d'intuition derrière ce numéro AUC, juste pour dissiper tout doute supplémentaire, validons-le en utilisant Scikit apprend l'implémentation AUC-ROC.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Sortir:
AUC for our sample data is 0.778>
Quand devrions-nous utiliser la métrique d’évaluation AUC-ROC ?
Il existe certains domaines dans lesquels l’utilisation de ROC-AUC pourrait ne pas être idéale. Dans les cas où l'ensemble de données est fortement déséquilibré, la courbe ROC peut donner une évaluation trop optimiste des performances du modèle . Ce biais d’optimisme est dû au fait que le taux de faux positifs (FPR) de la courbe ROC peut devenir très faible lorsque le nombre de négatifs réels est important.
En regardant la formule FPR,

nous observons ,
- La classe Négative est majoritaire, le dénominateur du FPR est dominé par les Vrais Négatifs, c'est pourquoi le FPR devient moins sensible aux changements de prédictions liés à la classe minoritaire (classe positive).
- Les courbes ROC peuvent être appropriées lorsque le coût des faux positifs et des faux négatifs est équilibré et que l'ensemble de données n'est pas fortement déséquilibré.
Dans ces cas-là, Courbes de rappel de précision peuvent être utilisés pour fournir une métrique d'évaluation alternative plus adaptée aux ensembles de données déséquilibrés, en se concentrant sur les performances du classificateur par rapport à la classe positive (minoritaire).
Spéculer les performances du modèle
- Une AUC élevée (proche de 1) indique un excellent pouvoir discriminant. Cela signifie que le modèle est efficace pour distinguer les deux classes et que ses prédictions sont fiables.
- Une AUC faible (proche de 0) suggère de mauvaises performances. Dans ce cas, le modèle a du mal à différencier les classes positives et négatives, et ses prédictions peuvent ne pas être fiables.
- Une AUC autour de 0,5 implique que le modèle fait essentiellement des suppositions aléatoires. Cela ne montre aucune capacité à séparer les classes, ce qui indique que le modèle n'apprend aucun modèle significatif à partir des données.
Comprendre la courbe AUC-ROC
Dans une courbe ROC, l'axe des x représente généralement le taux de faux positifs (FPR) et l'axe des y représente le taux de vrais positifs (TPR), également appelé sensibilité ou rappel. Ainsi, une valeur plus élevée sur l'axe des x (vers la droite) sur la courbe ROC indique un taux de faux positifs plus élevé, et une valeur plus élevée sur l'axe des y (vers le haut) indique un taux de vrais positifs plus élevé. La courbe ROC est un graphique. représentation du compromis entre le taux de vrais positifs et le taux de faux positifs à différents seuils. Il montre les performances d'un modèle de classification à différents seuils de classification. L'AUC (Area Under the Curve) est une mesure récapitulative des performances de la courbe ROC. Le choix du seuil dépend des exigences spécifiques du problème que vous essayez de résoudre et du compromis entre faux positifs et faux négatifs. acceptable dans votre contexte.
- Si vous souhaitez donner la priorité à la réduction des faux positifs (en minimisant les chances de qualifier quelque chose de positif alors qu'il ne l'est pas), vous pouvez choisir un seuil qui entraîne un taux de faux positifs plus faible.
- Si vous souhaitez donner la priorité à l’augmentation des vrais positifs (en capturant autant de vrais positifs que possible), vous pouvez choisir un seuil qui se traduit par un taux de vrais positifs plus élevé.
Prenons un exemple pour illustrer comment les courbes ROC sont générées pour différents seuils et comment un seuil particulier correspond à une matrice de confusion. Supposons que nous ayons un problème de classification binaire avec un modèle prédisant si un e-mail est du spam (positif) ou non (négatif).
Considérons les données hypothétiques,
Vraies étiquettes : [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Probabilités prédites : [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Cas 1 : Seuil = 0,5
Vraies étiquettes | Probabilités prédites | Étiquettes prédites |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrice de confusion basée sur les prédictions ci-dessus
| Prédiction = 0 | Prédiction = 1 |
|---|---|---|
Réel = 0 | TP=4 | FR=1 |
Réel = 1 erreur d'attribut python | FP=0 | NT=5 |
Par conséquent,
- Taux de vrais positifs (TPR) :
La proportion de positifs réels correctement identifiés par le classificateur est

- Taux de faux positifs (FPR) :
Proportion de négatifs réels classés à tort comme positifs



Ainsi, au seuil de 0,5 :
- Taux de vrai positif (sensibilité) : 0,8
- Taux de faux positifs : 0
L'interprétation est que le modèle, à ce seuil, identifie correctement 80 % des positifs réels (TPR) mais classe à tort 0 % des négatifs réels comme positifs (FPR).
En conséquence, pour différents seuils, nous obtiendrons ,
Cas 2 : Seuil = 0,7
Vraies étiquettes | Probabilités prédites | Étiquettes prédites |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Matrice de confusion basée sur les prédictions ci-dessus
| Prédiction = 0 | Prédiction = 1 |
|---|---|---|
Réel = 0 | TP=5 | FR=0 |
Réel = 1 | FP=2 | NT=3 |
Par conséquent,
- Taux de vrais positifs (TPR) :
La proportion de positifs réels correctement identifiés par le classificateur est

- Taux de faux positifs (FPR) :
Proportion de négatifs réels classés à tort comme positifs



Cas 3 : Seuil = 0,4
Vraies étiquettes | Probabilités prédites | Étiquettes prédites |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrice de confusion basée sur les prédictions ci-dessus
| Prédiction = 0 | Prédiction = 1 |
|---|---|---|
Réel = 0 | TP=4 | FR=1 |
Réel = 1 | FP=0 | NT=5 |
Par conséquent,
- Taux de vrais positifs (TPR) :
La proportion de positifs réels correctement identifiés par le classificateur est
- Taux de faux positifs (FPR) :
Proportion de négatifs réels classés à tort comme positifs
Cas 4 : Seuil = 0,2
Vraies étiquettes | Probabilités prédites | Étiquettes prédites |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrice de confusion basée sur les prédictions ci-dessus
| Prédiction = 0 | Prédiction = 1 |
|---|---|---|
Réel = 0 | TP=2 | FR=3 |
Réel = 1 | FP=0 | NT=5 |
Par conséquent,
- Taux de vrais positifs (TPR) :
La proportion de positifs réels correctement identifiés par le classificateur est

- Taux de faux positifs (FPR) :
Proportion de négatifs réels classés à tort comme positifs

Cas 5 : Seuil = 0,85
Vraies étiquettes | Probabilités prédites | Étiquettes prédites |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Matrice de confusion basée sur les prédictions ci-dessus
| Prédiction = 0 | Prédiction = 1 |
|---|---|---|
Réel = 0 | TP=5 | FR=0 |
Réel = 1 | FP=4 | NT=1 |
Par conséquent,
- Taux de vrais positifs (TPR) :
La proportion de positifs réels correctement identifiés par le classificateur est
- Taux de faux positifs (FPR) :
Proportion de négatifs réels classés à tort comme positifs


Sur la base du résultat ci-dessus, nous tracerons la courbe ROC
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Sortir:
Du graphique, il ressort que :
- La ligne pointillée grise représente le pire des cas, dans lequel les prédictions du modèle, c'est-à-dire TPR et FPR, sont les mêmes. Cette ligne diagonale est considérée comme le pire des cas, indiquant une probabilité égale de faux positifs et de faux négatifs.
- À mesure que les points s’écartent de la ligne de supposition aléatoire vers le coin supérieur gauche, les performances du modèle s’améliorent.
- L’aire sous la courbe (AUC) est une mesure quantitative de la capacité discriminante du modèle. Une valeur d'AUC plus élevée, plus proche de 1,0, indique des performances supérieures. La meilleure valeur d'ASC possible est de 1,0, correspondant à un modèle atteignant 100 % de sensibilité et 100 % de spécificité.
Au total, la courbe ROC (Receiver Operating Characteristic) sert de représentation graphique du compromis entre le taux de vrais positifs (sensibilité) et le taux de faux positifs d'un modèle de classification binaire à différents seuils de décision. Lorsque la courbe monte gracieusement vers le coin supérieur gauche, cela signifie la capacité louable du modèle à faire la distinction entre les instances positives et négatives sur une gamme de seuils de confiance. Cette trajectoire ascendante indique une performance améliorée, avec une sensibilité plus élevée obtenue tout en minimisant les faux positifs. Les seuils annotés, notés A, B, C, D et E, offrent des informations précieuses sur le comportement dynamique du modèle à différents niveaux de confiance.
Implémentation à l'aide de deux modèles différents
Installation des bibliothèques
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Afin de former les Forêt aléatoire et Régression logistique modèles et pour présenter leurs courbes ROC avec les scores AUC, l'algorithme crée des données de classification binaire artificielle.
Générer des données et diviser les données
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
En utilisant un rapport de répartition de 80-20, l'algorithme crée des données de classification binaire artificielles avec 20 caractéristiques, les divise en ensembles d'entraînement et de test et attribue une graine aléatoire pour garantir la reproductibilité.
Entraîner les différents modèles
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
À l'aide d'une graine aléatoire fixe pour garantir la répétabilité, la méthode initialise et entraîne un modèle de régression logistique sur l'ensemble d'apprentissage. De la même manière, il utilise les données d'entraînement et la même graine aléatoire pour initialiser et entraîner un modèle Random Forest avec 100 arbres.
Prédictions
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
En utilisant les données de test et un personnel formé Régression logistique modèle, le code prédit la probabilité de la classe positive. De la même manière, en utilisant les données du test, il utilise le modèle Random Forest entraîné pour produire des probabilités projetées pour la classe positive.
Création d'un dataframe
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
À l'aide des données de test, le code crée un DataFrame appelé test_df avec des colonnes intitulées True, Logistic et RandomForest, ajoutant de vraies étiquettes et des probabilités prédites à partir des modèles Random Forest et Logistic Regression.
Tracez la courbe ROC pour les modèles
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Sortir:

Le code génère un tracé avec des chiffres de 8 x 6 pouces. Il calcule la courbe AUC et ROC pour chaque modèle (Random Forest et Logistic Regression), puis trace la courbe ROC. Le Courbe ROC pour les devinettes aléatoires, est également représenté par une ligne pointillée rouge, et des étiquettes, un titre et une légende sont définis pour la visualisation.
Comment utiliser ROC-AUC pour un modèle multi-classes ?
Pour un environnement multi-classes, nous pouvons simplement utiliser la méthodologie un contre tous et vous aurez une courbe ROC pour chaque classe. Disons que vous avez quatre classes A, B, C et D, alors il y aurait des courbes ROC et des valeurs AUC correspondantes pour les quatre classes, c'est-à-dire qu'une fois A serait une classe et B, C et D combinés seraient les autres classes. , de même, B est une classe et A, C et D combinés comme d'autres classes, etc.
Les étapes générales d'utilisation d'AUC-ROC dans le contexte d'un modèle de classification multiclasse sont :
Méthodologie un contre tous :
- Pour chaque classe de votre problème multiclasse, traitez-la comme la classe positive tout en combinant toutes les autres classes dans la classe négative.
- Entraînez le classificateur binaire pour chaque classe par rapport au reste des classes.
Calculez l'AUC-ROC pour chaque classe :
- Ici, nous traçons la courbe ROC de la classe donnée par rapport au reste.
- Tracez les courbes ROC de chaque classe sur le même graphique. Chaque courbe représente les performances de discrimination du modèle pour une classe spécifique.
- Examinez les scores AUC pour chaque classe. Un score AUC plus élevé indique une meilleure discrimination pour cette classe particulière.
Implémentation de AUC-ROC dans la classification multiclasse
Importation de bibliothèques
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Le programme crée des données multiclasses artificielles, les divise en ensembles de formation et de test, puis utilise le Classificateur One-vs-Rest technique pour former des classificateurs à la fois pour la forêt aléatoire et la régression logistique. Enfin, il trace les courbes ROC multiclasses des deux modèles pour démontrer dans quelle mesure ils distinguent les différentes classes.
Génération de données et fractionnement
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Trois classes et vingt fonctionnalités constituent les données synthétiques multiclasses produites par le code. Après la binarisation des étiquettes, les données sont divisées en ensembles de formation et de test dans un rapport de 80 à 20.
Modèles de formation
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Le programme forme deux modèles multiclasses : un modèle de forêt aléatoire avec 100 estimateurs et un modèle de régression logistique avec le Approche un contre repos . Avec l'ensemble de données d'entraînement, les deux modèles sont ajustés.
Tracer la courbe AUC-ROC
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Sortir:

Les courbes ROC et les scores AUC des modèles Random Forest et Logistic Regression sont calculés par le code de chaque classe. Les courbes ROC multiclasses sont ensuite tracées, montrant les performances de discrimination de chaque classe et comportant une ligne qui représente une supposition aléatoire. Le graphique résultant offre une évaluation graphique des performances de classification des modèles.
Conclusion
Dans l'apprentissage automatique, les performances des modèles de classification binaire sont évaluées à l'aide d'une métrique cruciale appelée zone sous la caractéristique de fonctionnement du récepteur (AUC-ROC). À travers différents seuils de décision, il montre comment la sensibilité et la spécificité sont négociées. Une plus grande discrimination entre les instances positives et négatives est généralement présentée par un modèle avec un score AUC plus élevé. Alors que 0,5 dénote le hasard, 1 représente une performance sans faille. L'optimisation et la sélection du modèle sont facilitées par les informations utiles qu'offre la courbe AUC-ROC sur la capacité d'un modèle à discriminer entre les classes. Lorsque vous travaillez avec des ensembles de données déséquilibrés ou des applications où les faux positifs et les faux négatifs ont des coûts différents, cette mesure est particulièrement utile en tant que mesure globale.
FAQ sur la courbe AUC ROC dans l’apprentissage automatique
1. Qu'est-ce que la courbe AUC-ROC ?
Pour différents seuils de classification, le compromis entre le taux de vrais positifs (sensibilité) et le taux de faux positifs (spécificité) est représenté graphiquement par la courbe AUC-ROC.
2. À quoi ressemble une courbe AUC-ROC parfaite ?
Une aire de 1 sur une courbe AUC-ROC idéale signifierait que le modèle atteint une sensibilité et une spécificité optimales à tous les seuils.
3. Que signifie une valeur d'ASC de 0,5 ?
Une AUC de 0,5 indique que les performances du modèle sont comparables à celles du hasard. Cela suggère un manque de capacité de discrimination.
4. L'AUC-ROC peut-elle être utilisée pour la classification multiclasse ?
Réseau et Internet
AUC-ROC est fréquemment appliqué aux problèmes impliquant la classification binaire. Des variations telles que l'ASC macro-moyenne ou micro-moyenne peuvent être prises en compte pour la classification multiclasse.
5. En quoi la courbe AUC-ROC est-elle utile dans l'évaluation du modèle ?
La capacité d'un modèle à discriminer entre les classes est résumée de manière exhaustive par la courbe AUC-ROC. Lorsque vous travaillez avec des ensembles de données déséquilibrés, cela est particulièrement utile.