Le clustering ou l'analyse de cluster est une technique d'apprentissage automatique qui regroupe l'ensemble de données non étiqueté. On peut le définir comme «Une façon de regrouper les points de données en différents clusters, constitués de points de données similaires. Les objets présentant des similitudes possibles restent dans un groupe qui a moins ou pas de similitudes avec un autre groupe.
Pour ce faire, il recherche des modèles similaires dans l'ensemble de données non étiquetés, tels que la forme, la taille, la couleur, le comportement, etc., et les divise selon la présence et l'absence de ces modèles similaires.
C'est un apprentissage non supervisé méthode, donc aucune supervision n’est fournie à l’algorithme, et il traite l’ensemble de données non étiqueté.
Après avoir appliqué cette technique de clustering, chaque cluster ou groupe reçoit un ID de cluster. Le système ML peut utiliser cet identifiant pour simplifier le traitement d'ensembles de données volumineux et complexes.
La technique du clustering est couramment utilisée pour analyse de données statistiques.
Remarque : le clustering est quelque part similaire au algorithme de classification , mais la différence réside dans le type d'ensemble de données que nous utilisons. En classification, nous travaillons avec l'ensemble de données étiqueté, tandis qu'en clustering, nous travaillons avec l'ensemble de données non étiqueté.
Exemple : Comprenons la technique de clustering avec l'exemple réel de Mall : lorsque nous visitons un centre commercial, nous pouvons observer que les éléments ayant un usage similaire sont regroupés. Comme les t-shirts sont regroupés dans une section et les pantalons dans d'autres sections, de même, dans les sections de légumes, les pommes, les bananes, les mangues, etc., sont regroupées dans des sections séparées, afin que nous puissions facilement trouver les choses. La technique de clustering fonctionne également de la même manière. D'autres exemples de regroupement consistent à regrouper des documents en fonction du sujet.
La technique de clustering peut être largement utilisée dans diverses tâches. Certaines utilisations les plus courantes de cette technique sont :
- Segmentation du marché
- Analyse des données statistiques
- Analyse des réseaux sociaux
- Segmentation d'images
- Détection d'anomalies, etc.
En dehors de ces usages généraux, il est utilisé par les Amazone dans son système de recommandation pour fournir les recommandations selon la recherche passée de produits. Netflix utilise également cette technique pour recommander les films et les séries Web à ses utilisateurs en fonction de l'historique des vidéos regardées.
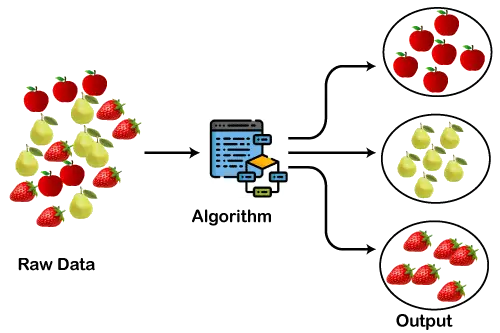
Le diagramme ci-dessous explique le fonctionnement de l'algorithme de clustering. On peut voir que les différents fruits sont répartis en plusieurs groupes aux propriétés similaires.
Types de méthodes de clustering
Les méthodes de clustering sont largement divisées en Clustering dur (le point de données appartient à un seul groupe) et Clustering souple (les points de données peuvent également appartenir à un autre groupe). Mais il existe également d’autres approches de clustering. Vous trouverez ci-dessous les principales méthodes de clustering utilisées en Machine Learning :
Partitionnement, clustering
Il s'agit d'un type de clustering qui divise les données en groupes non hiérarchiques. Il est également connu sous le nom de méthode basée sur le centroïde . L'exemple le plus courant de partitionnement en cluster est le Algorithme de clustering K-Means .
Dans ce type, l'ensemble de données est divisé en un ensemble de k groupes, où K est utilisé pour définir le nombre de groupes prédéfinis. Le centre du cluster est créé de telle manière que la distance entre les points de données d'un cluster est minimale par rapport au centre de gravité d'un autre cluster.

Clustering basé sur la densité
La méthode de regroupement basée sur la densité connecte les zones très denses en clusters, et les distributions de forme arbitraire sont formées tant que la région dense peut être connectée. Cet algorithme le fait en identifiant différents clusters dans l'ensemble de données et connecte les zones à haute densité en clusters. Les zones denses de l’espace de données sont séparées les unes des autres par des zones plus clairsemées.
Ces algorithmes peuvent avoir des difficultés à regrouper les points de données si l'ensemble de données a des densités variables et des dimensions élevées.

Clustering basé sur un modèle de distribution
Dans la méthode de regroupement basée sur un modèle de distribution, les données sont divisées en fonction de la probabilité d'appartenance d'un ensemble de données à une distribution particulière. Le regroupement se fait en supposant certaines distributions communément Distribution gaussienne .
L'exemple de ce type est le Algorithme de clustering d'attente-maximisation qui utilise des modèles de mélange gaussien (GMM).

Classification hiérarchique
Le clustering hiérarchique peut être utilisé comme alternative au clustering partitionné car il n'est pas nécessaire de spécifier à l'avance le nombre de clusters à créer. Dans cette technique, l'ensemble de données est divisé en clusters pour créer une structure arborescente, également appelée dendrogramme . Les observations ou n'importe quel nombre de grappes peuvent être sélectionnées en coupant l'arbre au bon niveau. L'exemple le plus courant de cette méthode est la Algorithme hiérarchique agglomératif .

Clustering flou
Le clustering flou est un type de méthode logicielle dans laquelle un objet de données peut appartenir à plusieurs groupes ou clusters. Chaque ensemble de données possède un ensemble de coefficients d'appartenance, qui dépendent du degré d'appartenance à un cluster. Algorithme C-means flou est l'exemple de ce type de clustering ; il est parfois également connu sous le nom d'algorithme Fuzzy k-means.
Algorithmes de clustering
Les algorithmes de clustering peuvent être divisés en fonction de leurs modèles expliqués ci-dessus. Il existe différents types d’algorithmes de clustering publiés, mais seuls quelques-uns sont couramment utilisés. L'algorithme de clustering est basé sur le type de données que nous utilisons. Par exemple, certains algorithmes doivent deviner le nombre de clusters dans l'ensemble de données donné, tandis que d'autres doivent trouver la distance minimale entre l'observation de l'ensemble de données.
Nous discutons ici principalement des algorithmes de clustering populaires qui sont largement utilisés dans l'apprentissage automatique :
Applications du clustering
Vous trouverez ci-dessous quelques applications communément connues de la technique de clustering dans le Machine Learning :