Nous lisons les structures de données linéaires comme un tableau, une liste chaînée, une pile et une file d'attente dans lesquelles tous les éléments sont disposés de manière séquentielle. Les différentes structures de données sont utilisées pour différents types de données.
Certains facteurs sont pris en compte pour choisir la structure des données :
Un arbre est également l'une des structures de données qui représentent les données hiérarchiques. Supposons que nous souhaitions afficher les employés et leurs postes sous forme hiérarchique, cela peut être représenté comme indiqué ci-dessous :
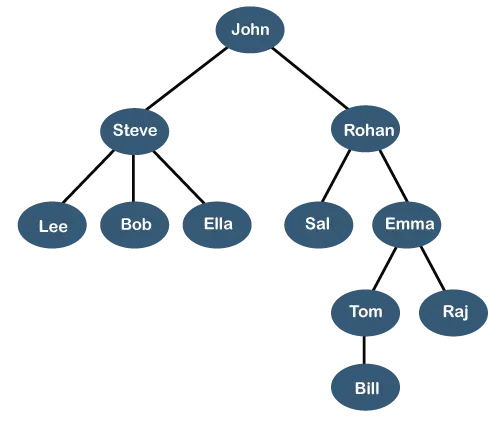
L'arbre ci-dessus montre le hiérarchie de l'organisation d'une certaine entreprise. Dans la structure ci-dessus, John est le PDG de l'entreprise, et John a deux subordonnés directs nommés Steve et Rohan . Steve a trois subordonnés directs nommés Lee, Bob, Ella où Steve est un gestionnaire. Bob a deux subordonnés directs nommés Devoir et Emma . Emma a deux subordonnés directs nommés À M et Raj . Tom a un subordonné direct nommé Facture . Cette structure logique particulière est connue sous le nom de Arbre . Sa structure est similaire à celle de l'arbre réel, c'est pourquoi on l'appelle un Arbre . Dans cette structure, le racine est au sommet et ses branches se déplacent vers le bas. Par conséquent, nous pouvons dire que la structure de données Tree est un moyen efficace de stocker les données de manière hiérarchique.
Comprenons quelques points clés de la structure de données Tree.
- Une structure de données arborescente est définie comme un ensemble d'objets ou d'entités appelés nœuds qui sont liés entre eux pour représenter ou simuler une hiérarchie.
- Une structure de données arborescente est une structure de données non linéaire car elle n'est pas stockée de manière séquentielle. Il s'agit d'une structure hiérarchique car les éléments d'un arbre sont disposés sur plusieurs niveaux.
- Dans la structure de données Tree, le nœud le plus élevé est appelé nœud racine. Chaque nœud contient des données et les données peuvent être de n'importe quel type. Dans l'arborescence ci-dessus, le nœud contient le nom de l'employé, le type de données serait donc une chaîne.
- Chaque nœud contient des données et le lien ou la référence d'autres nœuds qui peuvent être appelés enfants.
Quelques termes de base utilisés dans la structure de données arborescente.
Considérons la structure arborescente, présentée ci-dessous :

Dans la structure ci-dessus, chaque nœud est étiqueté avec un numéro. Chaque flèche montrée dans la figure ci-dessus est connue sous le nom de lien entre les deux nœuds.
Propriétés de la structure de données arborescente

Sur la base des propriétés de la structure de données Tree, les arbres sont classés en différentes catégories.
Implémentation de l'arbre
La structure de données arborescente peut être créée en créant les nœuds dynamiquement à l'aide des pointeurs. L'arborescence en mémoire peut être représentée comme indiqué ci-dessous :

La figure ci-dessus montre la représentation de la structure arborescente des données dans la mémoire. Dans la structure ci-dessus, le nœud contient trois champs. Le deuxième champ stocke les données ; le premier champ stocke l'adresse de l'enfant de gauche et le troisième champ stocke l'adresse de l'enfant de droite.
En programmation, la structure d'un nœud peut être définie comme :
struct node { int data; struct node *left; struct node *right; } La structure ci-dessus ne peut être définie que pour les arbres binaires car l'arbre binaire peut avoir au maximum deux enfants et les arbres génériques peuvent avoir plus de deux enfants. La structure du nœud pour les arbres génériques serait différente de celle de l'arbre binaire.
conversion de date en chaîne
Applications des arbres
Voici les applications des arbres :
Types de structure de données arborescente
Voici les types de structure de données arborescente :

Il peut y avoir n nombre de sous-arbres dans un arbre général. Dans l'arborescence générale, les sous-arbres ne sont pas ordonnés car les nœuds du sous-arbre ne peuvent pas être ordonnés.
Chaque arbre non vide a un bord descendant, et ces bords sont connectés aux nœuds appelés nœuds enfants . Le nœud racine est étiqueté avec le niveau 0. Les nœuds qui ont le même parent sont appelés frères et sœurs .

Pour en savoir plus sur l'arbre binaire, cliquez sur le lien ci-dessous :
https://www.javatpoint.com/binary-tree
Chaque nœud du sous-arbre de gauche doit contenir une valeur inférieure à la valeur du nœud racine, et la valeur de chaque nœud du sous-arbre de droite doit être supérieure à la valeur du nœud racine.
Un nœud peut être créé à l'aide d'un type de données défini par l'utilisateur appelé structurer, comme indiqué ci-dessous:
struct node { int data; struct node *left; struct node *right; } Ce qui précède est la structure de nœud avec trois champs : champ de données, le deuxième champ est le pointeur gauche du type de nœud et le troisième champ est le pointeur droit du type de nœud.
Pour en savoir plus sur l'arbre de recherche binaire, cliquez sur le lien ci-dessous :
https://www.javatpoint.com/binary-search-tree
C'est l'un des types de l'arbre binaire, ou on peut dire que c'est une variante de l'arbre de recherche binaire. L’arbre AVL satisfait la propriété du arbre binaire ainsi que du arbre de recherche binaire . Il s'agit d'un arbre de recherche binaire auto-équilibré qui a été inventé par Adelson Velsky Lindas . Ici, l’auto-équilibrage signifie équilibrer les hauteurs du sous-arbre gauche et du sous-arbre droit. Cet équilibrage se mesure en termes de facteur d'équilibrage .
On peut considérer un arbre comme un arbre AVL si l'arbre obéit à l'arbre de recherche binaire ainsi qu'à un facteur d'équilibrage. Le facteur d’équilibrage peut être défini comme le différence entre la hauteur du sous-arbre gauche et la hauteur du sous-arbre droit . La valeur du facteur d'équilibrage doit être 0, -1 ou 1 ; par conséquent, chaque nœud de l'arborescence AVL doit avoir la valeur du facteur d'équilibrage soit 0, -1 ou 1.
Pour en savoir plus sur l'arborescence AVL, cliquez sur le lien ci-dessous :
https://www.javatpoint.com/avl-tree
L'arbre rouge-noir est l'arbre de recherche binaire. La condition préalable à l’arbre Rouge-Noir est que nous connaissions l’arbre de recherche binaire. Dans un arbre de recherche binaire, la valeur du sous-arbre gauche doit être inférieure à la valeur de ce nœud et la valeur du sous-arbre droit doit être supérieure à la valeur de ce nœud. Comme nous savons que la complexité temporelle de la recherche binaire dans le cas moyen est log2n, le meilleur des cas est O(1) et le pire des cas est O(n).
Lorsqu'une opération est effectuée sur l'arborescence, nous voulons que notre arborescence soit équilibrée afin que toutes les opérations comme la recherche, l'insertion, la suppression, etc. prennent moins de temps, et toutes ces opérations auront la complexité temporelle de enregistrer2n.
méthode java
L'arbre rouge-noir est un arbre de recherche binaire auto-équilibré. L'arbre AVL est également un arbre de recherche binaire à équilibrage de hauteur. pourquoi avons-nous besoin d'un arbre rouge-noir . Dans l’arbre AVL, on ne sait pas combien de rotations seraient nécessaires pour équilibrer l’arbre, mais dans l’arbre Rouge-noir, un maximum de 2 rotations sont nécessaires pour équilibrer l’arbre. Il contient un bit supplémentaire qui représente soit la couleur rouge, soit la couleur noire d'un nœud pour assurer l'équilibrage de l'arborescence.
La structure de données de l'arbre évasé est également un arbre de recherche binaire dans lequel l'élément récemment accédé est placé à la racine de l'arbre en effectuant certaines opérations de rotation. Ici, ébrasement signifie le nœud récemment accédé. C'est un auto-équilibrage arbre de recherche binaire n'ayant pas de condition d'équilibre explicite comme AVL arbre.
Il se peut que la hauteur de l'arbre évasé ne soit pas équilibrée, c'est-à-dire que la hauteur des sous-arbres gauche et droit peut différer, mais les opérations dans l'arbre évasé suivent l'ordre suivant. calme moment où n est le nombre de nœuds.
L'arbre évasé est un arbre équilibré mais il ne peut pas être considéré comme un arbre équilibré en hauteur car après chaque opération, une rotation est effectuée ce qui conduit à un arbre équilibré.
La structure de données Treap provient de la structure de données Tree and Heap. Ainsi, il comprend les propriétés des structures de données Tree et Heap. Dans l'arbre de recherche binaire, chaque nœud du sous-arbre de gauche doit être égal ou inférieur à la valeur du nœud racine et chaque nœud du sous-arbre de droite doit être égal ou supérieur à la valeur du nœud racine. Dans la structure de données en tas, les sous-arbres droit et gauche contiennent des clés plus grandes que la racine ; par conséquent, nous pouvons dire que le nœud racine contient la valeur la plus basse.
Dans la structure de données treap, chaque nœud possède à la fois clé et priorité où la clé est dérivée de l'arbre de recherche binaire et la priorité est dérivée de la structure de données du tas.
Le Treap la structure des données suit deux propriétés indiquées ci-dessous :
- Enfant droit d'un nœud> = nœud actuel et enfant gauche d'un nœud<=current node (binary tree)< li>
- Les enfants de tout sous-arbre doivent être supérieurs au nœud (tas)
B-tree est un arbre équilibré à ma manière arbre où m définit l'ordre de l'arbre. Jusqu'à présent, nous lisons que le nœud ne contient qu'une seule clé mais que le b-tree peut avoir plus d'une clé et plus de 2 enfants. Il conserve toujours les données triées. Dans un arbre binaire, il est possible que les nœuds feuilles soient à différents niveaux, mais dans un arbre b, tous les nœuds feuilles doivent être au même niveau.
Si l'ordre est m, alors le nœud a les propriétés suivantes :
- Chaque nœud d'un arbre B peut avoir un maximum m enfants
- Pour un minimum d'enfants, un nœud feuille a 0 enfant, un nœud racine a un minimum de 2 enfants et un nœud interne a un plafond minimum de m/2 enfants. Par exemple, la valeur de m est 5, ce qui signifie qu'un nœud peut avoir 5 enfants et que les nœuds internes peuvent contenir au maximum 3 enfants.
- Chaque nœud a un maximum de clés (m-1).
Le nœud racine doit contenir au minimum 1 clé et tous les autres nœuds doivent contenir au moins plafond de m/2 moins 1 clés.