Stream a été introduit dans Java8 l'API Stream est utilisée pour traiter des collections d'objets. Un flux en Java est une séquence d'objets qui prend en charge diverses méthodes pouvant être canalisées pour produire le résultat souhaité.
Utilisation de Stream en Java
Les utilisations de Stream en Java sont mentionnées ci-dessous :
- L'API Stream est un moyen d'exprimer et de traiter des collections d'objets.
- Permettez-nous d'effectuer des opérations telles que le filtrage, la réduction et le tri des mappages.
Comment créer un flux Java
La création de Java Stream est l'une des étapes les plus élémentaires avant d'envisager les fonctionnalités de Java Stream. Vous trouverez ci-dessous la syntaxe donnée pour déclarer un flux Java.
listes Java
Syntaxe
Flux
flux;
Ici, T est soit un objet de classe, soit un type de données en fonction de la déclaration.
Fonctionnalités du flux Java
Les fonctionnalités des flux Java sont mentionnées ci-dessous :
- Un Stream n’est pas une structure de données ; il prend simplement l'entrée des tableaux de collections ou des canaux d'E/S.
- Les flux ne modifient pas les données originales ; ils ne produisent des résultats qu’en utilisant leurs méthodes.
- Les opérations intermédiaires (comme la carte de filtre, etc.) sont paresseuses et renvoient un autre Stream afin que vous puissiez les enchaîner.
- Une opération de terminal (comme collect forEach count) termine le flux et donne le résultat final.
Différentes opérations sur les flux
Il existe deux types d'opérations dans les flux :
- Opérations intermédiaires
- Opérations des terminaux
Opérations intermédiaires
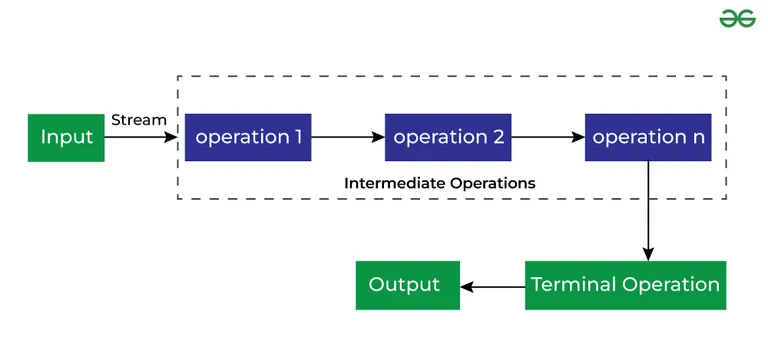
Les opérations intermédiaires sont les types d’opérations dans lesquelles plusieurs méthodes sont enchaînées à la suite.
Caractéristiques des opérations intermédiaires
- Les méthodes s’enchaînent.
- Les opérations intermédiaires transforment un flux en un autre flux.
- Il active le concept de filtrage dans lequel une méthode filtre les données et les transmet à une autre méthode après traitement.
Opérations intermédiaires importantes
Il y a quelques opérations intermédiaires mentionnées ci-dessous :
1. carte() : La méthode map est utilisée pour renvoyer un flux constitué des résultats de l'application de la fonction donnée aux éléments de ce flux.
Syntaxe:
Flux carte(Fonctionmappeur)
2. filtre() : La méthode de filtrage est utilisée pour sélectionner des éléments selon le prédicat passé en argument.
Syntaxe:
Flux
filtre(Prédicatprédicat)
3. trié() : La méthode sorted est utilisée pour trier le flux.
Syntaxe:
Flux
trié()
Fluxtrié (Comparateurcomparateur)
4. flatMap() : L'opération flatMap dans Java Streams est utilisée pour aplatir un flux de collections en un seul flux d'éléments.
Syntaxe:
Flux flatMap(Fonction> mappeur)
5. distinct() : Supprime les éléments en double. Il renvoie un flux composé d'éléments distincts (selon Object.equals(Object)).
Syntaxe:
Flux
distinct()
6. coup d'oeil() : Effectue une action sur chaque élément sans modifier le flux. Il renvoie un flux composé des éléments de ce flux, effectuant en outre l'action fournie sur chaque élément au fur et à mesure que les éléments sont consommés à partir du flux résultant.
Syntaxe:
Flux
coup d'oeil (Consommateuraction)
Programme Java qui démontre l'utilisation de toutes les opérations intermédiaires :
Javaimport java.util.Arrays; import java.util.HashSet; import java.util.List; import java.util.Set; import java.util.stream.Collectors; public class StreamIntermediateOperationsExample { public static void main(String[] args) { // List of lists of names List<List<String>> listOfLists = Arrays.asList( Arrays.asList('Reflection' 'Collection' 'Stream') Arrays.asList('Structure' 'State' 'Flow') Arrays.asList('Sorting' 'Mapping' 'Reduction' 'Stream') ); // Create a set to hold intermediate results Set<String> intermediateResults = new HashSet<>(); // Stream pipeline demonstrating various intermediate operations List<String> result = listOfLists.stream() .flatMap(List::stream) .filter(s -> s.startsWith('S')) .map(String::toUpperCase) .distinct() .sorted() .peek(s -> intermediateResults.add(s)) .collect(Collectors.toList()); // Print the intermediate results System.out.println('Intermediate Results:'); intermediateResults.forEach(System.out::println); // Print the final result System.out.println('Final Result:'); result.forEach(System.out::println); } }
Sortir
Intermediate Results: STRUCTURE STREAM STATE SORTING Final Result: SORTING STATE STREAM STRUCTURE
Explication:
- Le listOfLists est créé comme une liste contenant d’autres listes de chaînes.
- flatMap(Liste::stream): Aplatit les listes imbriquées en un seul flux de chaînes.
- filtre(s -> s.startsWith('S')) : Filtre les chaînes pour inclure uniquement celles qui commencent par « S ».
- map(String::toUpperCase) : convertit chaque chaîne du flux en majuscules.
- distinct() : Supprime toutes les chaînes en double.
- trié() : Trie les chaînes résultantes par ordre alphabétique.
- coup d'oeil(...): Ajoute chaque élément traité à l’ensemble middleResults pour une inspection intermédiaire.
- collect(Collectors.toList()) : Collecte les chaînes finales traitées dans une liste appelée résultat.
Le programme imprime les résultats intermédiaires stockés dans l’ensemble middleResults. Enfin, il imprime la liste des résultats qui contient les chaînes entièrement traitées après toutes les opérations de flux.
Opérations des terminaux
Les opérations de terminal sont le type d’opérations qui renvoient le résultat. Ces opérations ne sont pas traitées davantage, elles renvoient simplement une valeur de résultat final.
Opérations importantes du terminal
1. collecter() : La méthode collect permet de renvoyer le résultat des opérations intermédiaires effectuées sur le flux.
Syntaxe:
angles adjacents
R collect(Collecteurcollectionneur)
2. pourChaque() : La méthode forEach est utilisée pour parcourir chaque élément du flux.
Syntaxe:
void forEach (Consommateuraction)
3. réduire() : La méthode de réduction est utilisée pour réduire les éléments d’un flux à une seule valeur. La méthode de réduction prend un BinaryOperator comme paramètre.
Syntaxe:
T réduire(T identité BinaryOperator
accumulateur)
Facultatifréduire (opérateur binaire accumulateur)
4. compter() : renvoie le nombre d'éléments dans le flux.
Syntaxe:
compte long()
5. trouverPremier() : Renvoie le premier élément du flux s'il est présent.
Syntaxe:
Facultatif
trouverPremier() méthode égale java
6. allMatch() : Vérifie si tous les éléments du flux correspondent à un prédicat donné.
Syntaxe:
booléen allMatch(Prédicatprédicat)
7. N'importe quelle correspondance () : Vérifie si un élément du flux correspond à un prédicat donné.
Syntaxe:
Boolean Anymatch (Prédicatprédicat)
Ici, la variable ans se voit attribuer 0 comme valeur initiale et i y est ajouté.
Note: Les opérations intermédiaires s'exécutent sur la base du concept d'évaluation paresseuse qui garantit que chaque méthode renvoie une valeur fixe (opération de terminal) avant de passer à la méthode suivante.
Programme Java utilisant toutes les opérations du terminal :
Javaimport java.util.*; import java.util.stream.Collectors; public class StreamTerminalOperationsExample { public static void main(String[] args) { // Sample data List<String> names = Arrays.asList( 'Reflection' 'Collection' 'Stream' 'Structure' 'Sorting' 'State' ); // forEach: Print each name System.out.println('forEach:'); names.stream().forEach(System.out::println); // collect: Collect names starting with 'S' into a list List<String> sNames = names.stream() .filter(name -> name.startsWith('S')) .collect(Collectors.toList()); System.out.println('ncollect (names starting with 'S'):'); sNames.forEach(System.out::println); // reduce: Concatenate all names into a single string String concatenatedNames = names.stream().reduce( '' (partialString element) -> partialString + ' ' + element ); System.out.println('nreduce (concatenated names):'); System.out.println(concatenatedNames.trim()); // count: Count the number of names long count = names.stream().count(); System.out.println('ncount:'); System.out.println(count); // findFirst: Find the first name Optional<String> firstName = names.stream().findFirst(); System.out.println('nfindFirst:'); firstName.ifPresent(System.out::println); // allMatch: Check if all names start with 'S' boolean allStartWithS = names.stream().allMatch( name -> name.startsWith('S') ); System.out.println('nallMatch (all start with 'S'):'); System.out.println(allStartWithS); // anyMatch: Check if any name starts with 'S' boolean anyStartWithS = names.stream().anyMatch( name -> name.startsWith('S') ); System.out.println('nanyMatch (any start with 'S'):'); System.out.println(anyStartWithS); } }
Sortir:
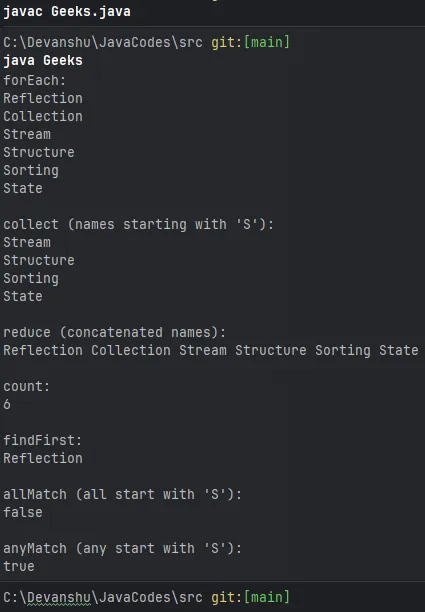 Sortir
SortirExplication:
- La liste des noms est créée avec des exemples de chaînes.
- pourChacun : Imprime chaque nom de la liste.
- collecter : Filtre les noms commençant par « S » et les rassemble dans une nouvelle liste.
- réduire : Concatène tous les noms en une seule chaîne.
- compter : Compte le nombre total de noms.
- trouverPremier : recherche et imprime le premier nom de la liste.
- toutMatch : Vérifie si tous les noms commencent par 'S'.
- malchanceux : Vérifie si un nom commence par 'S'.
Le programme imprime chaque nom commençant par « S », les noms concaténés, le nombre de noms, le prénom, si tous les noms commencent par « S » et si un nom commence par « S ».
Avantage de Java Stream
Il existe certains avantages pour lesquels nous utilisons Stream en Java, comme mentionné ci-dessous :
- Pas de stockage
- Pipeline de fonctions
- Paresse
- Peut être infini
- Peut être parallélisé
- Peut être créé à partir de tableaux de collections Fichiers Lignes Méthodes dans Stream IntStream etc.
Cas d'utilisation réels des flux Java
Les flux sont largement utilisés dans les applications Java modernes pour :
- Informatique
- Pour traiter les réponses JSON/XML
- Pour les opérations de base de données
- Traitement simultané