BERT, un acronyme pour les représentations d'encodeurs bidirectionnels à partir de transformateurs , se présente comme un logiciel open source cadre d'apprentissage automatique conçu pour le domaine de traitement du langage naturel (NLP) . Créé en 2018, ce framework a été conçu par des chercheurs de Google AI Language. L’article vise à explorer les architecture, fonctionnement et applications de BERT .
Qu’est-ce que le BERT ?
BERT (Représentations d'encodeurs bidirectionnels à partir de transformateurs) exploite un réseau neuronal basé sur un transformateur pour comprendre et générer un langage de type humain. BERT utilise une architecture uniquement encodeur. Dans la version originale Architecture du transformateur , il existe à la fois des modules d'encodeur et de décodeur. La décision d'utiliser une architecture uniquement encodeur dans BERT suggère de mettre l'accent sur la compréhension des séquences d'entrée plutôt que sur la génération de séquences de sortie.
Approche bidirectionnelle du BERT
Les modèles linguistiques traditionnels traitent le texte de manière séquentielle, soit de gauche à droite, soit de droite à gauche. Cette méthode limite la conscience du modèle au contexte immédiat précédant le mot cible. BERT utilise une approche bidirectionnelle prenant en compte à la fois le contexte gauche et droit des mots dans une phrase, au lieu d'analyser le texte de manière séquentielle, BERT examine simultanément tous les mots d'une phrase.
Exemple : La rive est située au _______ de la rivière.
Dans un modèle unidirectionnel, la compréhension du blanc dépendrait fortement des mots précédents, et le modèle pourrait avoir du mal à discerner si la banque fait référence à une institution financière ou au bord de la rivière.
BERT, étant bidirectionnel, considère simultanément le contexte gauche (la rive est située sur le) et droit (de la rivière), permettant une compréhension plus nuancée. Il comprend que le mot manquant est probablement lié à la situation géographique de la banque, démontrant la richesse contextuelle qu'apporte l'approche bidirectionnelle.
Pré-formation et mise au point
Le modèle BERT subit un processus en deux étapes :
- Pré-formation sur de grandes quantités de texte non étiqueté pour apprendre les intégrations contextuelles.
- Affinement des données étiquetées pour des besoins spécifiques PNL Tâches.
Pré-formation sur les Big Data
- BERT est pré-entraîné sur une grande quantité de données texte non étiquetées. Le modèle apprend les intégrations contextuelles, qui sont les représentations de mots qui prennent en compte leur contexte environnant dans une phrase.
- BERT s'engage dans diverses tâches de pré-formation non supervisées. Par exemple, il peut apprendre à prédire les mots manquants dans une phrase (modèle de langage masqué ou tâche MLM), à comprendre la relation entre deux phrases ou à prédire la phrase suivante d'une paire.
Affinement des données étiquetées
- Après la phase de pré-formation, le modèle BERT, armé de ses intégrations contextuelles, est ensuite affiné pour des tâches spécifiques de traitement du langage naturel (NLP). Cette étape adapte le modèle à des applications plus ciblées en adaptant sa compréhension générale du langage aux nuances de la tâche particulière.
- BERT est affiné à l'aide de données étiquetées spécifiques aux tâches d'intérêt en aval. Ces tâches peuvent inclure l'analyse des sentiments, la réponse aux questions, reconnaissance d'entité nommée , ou toute autre application PNL. Les paramètres du modèle sont ajustés pour optimiser ses performances en fonction des exigences particulières de la tâche à accomplir.
L'architecture unifiée de BERT lui permet de s'adapter à diverses tâches en aval avec des modifications minimes, ce qui en fait un outil polyvalent et très efficace dans compréhension du langage naturel et le traitement.
Comment fonctionne le BERT ?
BERT est conçu pour générer un modèle de langage, seul le mécanisme d'encodeur est utilisé. La séquence de jetons est transmise à l'encodeur du transformateur. Ces jetons sont d'abord intégrés dans des vecteurs puis traités dans le réseau neuronal. La sortie est une séquence de vecteurs, chacun correspondant à un jeton d'entrée, fournissant des représentations contextualisées.
Lors de la formation de modèles linguistiques, définir un objectif de prédiction est un défi. De nombreux modèles prédisent le mot suivant dans une séquence, ce qui constitue une approche directionnelle et peut limiter l'apprentissage du contexte. BERT relève ce défi avec deux stratégies de formation innovantes :
- Modèle de langage masqué (MLM)
- Prédiction de la phrase suivante (NSP)
1. Modèle de langage masqué (MLM)
Dans le processus de pré-entraînement de BERT, une partie des mots de chaque séquence d'entrée est masquée et le modèle est entraîné pour prédire les valeurs originales de ces mots masqués en fonction du contexte fourni par les mots environnants.
En termes simples,
- Mots de masquage : Avant que BERT n'apprenne des phrases, il cache certains mots (environ 15 %) et les remplace par un symbole spécial, comme [MASK].
- Deviner les mots cachés : Le travail de BERT consiste à découvrir ce que sont ces mots cachés en regardant les mots qui les entourent. C’est comme un jeu de devinettes où certains mots manquent, et BERT essaie de combler les vides.
- Comment BERT apprend :
- BERT ajoute une couche spéciale au-dessus de son système d'apprentissage pour faire ces suppositions. Il vérifie ensuite à quel point ses suppositions sont proches des mots cachés réels.
- Pour ce faire, il convertit ses suppositions en probabilités, en disant : je pense que ce mot est X, et j’en suis tout à fait sûr.
- Attention particulière aux mots cachés
- L'objectif principal de BERT pendant la formation est de comprendre correctement ces mots cachés. Il ne se soucie pas de prédire les mots qui ne sont pas cachés.
- En effet, le véritable défi consiste à déterminer les parties manquantes, et cette stratégie aide BERT à vraiment comprendre le sens et le contexte des mots.
En termes techniques,
- BERT ajoute une couche de classification au-dessus de la sortie de l'encodeur. Cette couche est cruciale pour prédire les mots masqués.
- Les vecteurs de sortie de la couche de classification sont multipliés par la matrice d'intégration, les transformant en dimension de vocabulaire. Cette étape permet d'aligner les représentations prédites avec l'espace du vocabulaire.
- La probabilité de chaque mot du vocabulaire est calculée à l'aide de la Fonction d'activation SoftMax . Cette étape génère une distribution de probabilité sur l'ensemble du vocabulaire pour chaque position masquée.
- La fonction de perte utilisée lors de l'entraînement ne considère que la prédiction des valeurs masquées. Le modèle est pénalisé pour l’écart entre ses prédictions et les valeurs réelles des mots masqués.
- Le modèle converge plus lentement que les modèles directionnels. En effet, lors de l'entraînement, BERT se préoccupe uniquement de prédire les valeurs masquées, ignorant la prédiction des mots non masqués. La sensibilisation accrue au contexte obtenue grâce à cette stratégie compense la convergence plus lente.
2. Prédiction de la prochaine phrase (NSP)
BERT prédit si la deuxième phrase est connectée à la première. Cela se fait en transformant la sortie du jeton [CLS] en un vecteur de forme 2 × 1 à l'aide d'une couche de classification, puis en calculant la probabilité que la deuxième phrase suive la première à l'aide de SoftMax.
- Au cours du processus de formation, BERT apprend à comprendre la relation entre des paires de phrases, en prédisant si la deuxième phrase suit la première dans le document original.
- 50 % des paires d'entrées ont la deuxième phrase comme phrase suivante dans le document original, et les 50 % restants ont une phrase choisie au hasard.
- Pour aider le modèle à distinguer les paires de phrases connectées et déconnectées. L'entrée est traitée avant d'entrer dans le modèle :
- Un jeton [CLS] est inséré au début de la première phrase et un jeton [SEP] est ajouté à la fin de chaque phrase.
- Une phrase incorporée indiquant la phrase A ou la phrase B est ajoutée à chaque jeton.
- Une intégration positionnelle indique la position de chaque jeton dans la séquence.
- BERT prédit si la deuxième phrase est connectée à la première. Cela se fait en transformant la sortie du jeton [CLS] en un vecteur de forme 2 × 1 à l'aide d'une couche de classification, puis en calculant la probabilité que la deuxième phrase suive la première à l'aide de SoftMax.
Pendant la formation du modèle BERT, le Masked LM et la Next Sentence Prediction sont formés ensemble. Le modèle vise à minimiser la fonction de perte combinée du Masked LM et de la prédiction de la phrase suivante, conduisant à un modèle de langage robuste avec des capacités améliorées de compréhension du contexte au sein des phrases et des relations entre les phrases.
Pourquoi entraîner ensemble Masked LM et Next Sentence Prediction ?
Masked LM aide BERT à comprendre le contexte dans une phrase et Prédiction de la phrase suivante aide BERT à saisir le lien ou la relation entre des paires de phrases. Par conséquent, la formation des deux stratégies ensemble garantit que BERT acquiert une compréhension large et complète du langage, capturant à la fois les détails des phrases et le flux entre les phrases.
Architectures BERT
L'architecture de BERT est un codeur de transformateur bidirectionnel multicouche qui est assez similaire au modèle de transformateur. Une architecture de transformateur est un réseau codeur-décodeur qui utilise attention personnelle côté codeur et attention côté décodeur.
- BERTEBASEa 1 2 couches dans la pile Encoder tandis que BERTGRANDa 24 couches dans la pile Encoder . Ce sont plus que l'architecture Transformer décrite dans l'article original ( 6 couches d'encodeur ).
- Les architectures BERT (BASE et LARGE) disposent également de réseaux feedforward plus grands (respectivement 768 et 1024 unités cachées), et plus de têtes d'attention (12 et 16 respectivement) que l'architecture Transformer suggérée dans l'article original. Il contient 512 unités cachées et 8 têtes d'attention .
- BERTEBASEcontient 110 millions de paramètres tandis que BERTGRANDa 340 millions de paramètres.

Architecture BERT BASE et BERT LARGE.
Ce modèle prend le CLS jeton en entrée en premier, puis il est suivi d'une séquence de mots en entrée. Ici, CLS est un jeton de classification. Il transmet ensuite l'entrée aux couches ci-dessus. Chaque couche s'applique attention personnelle et transmet le résultat via un réseau de rétroaction, puis il le transmet à l'encodeur suivant. Le modèle génère un vecteur de taille cachée ( 768 pour BASE BERT). Si nous voulons générer un classificateur à partir de ce modèle, nous pouvons prendre la sortie correspondant au jeton CLS.
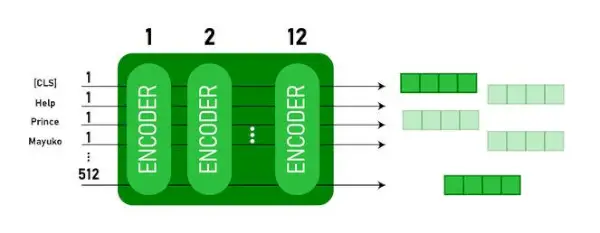
Sortie BERT sous forme d'intégrations
Désormais, ce vecteur entraîné peut être utilisé pour effectuer un certain nombre de tâches telles que la classification, la traduction, etc. Par exemple, le papier obtient d'excellents résultats simplement en utilisant une seule couche. Réseau neuronal sur le modèle BERT dans la tâche de classification.
Comment utiliser le modèle BERT en PNL ?
BERT peut être utilisé pour diverses tâches de traitement du langage naturel (NLP) telles que :
1. Tâche de classification
- BERT peut être utilisé pour des tâches de classification telles que analyse des sentiments , le but est de classer le texte en différentes catégories (positif/négatif/neutre), BERT peut être utilisé en ajoutant une couche de classification en haut de la sortie du transformateur pour le jeton [CLS].
- Le jeton [CLS] représente les informations agrégées de l'ensemble de la séquence d'entrée. Cette représentation regroupée peut ensuite être utilisée comme entrée pour une couche de classification afin d'effectuer des prédictions pour la tâche spécifique.
2. Réponse aux questions
- Dans les tâches de réponse aux questions, où le modèle doit localiser et marquer la réponse dans une séquence de texte donnée, BERT peut être formé à cet effet.
- BERT est formé à la réponse aux questions en apprenant deux vecteurs supplémentaires qui marquent le début et la fin de la réponse. Pendant la formation, le modèle reçoit des questions et des passages correspondants, et il apprend à prédire les positions de début et de fin de la réponse dans le passage.
3. Reconnaissance d'entité nommée (NER)
- BERT peut être utilisé pour NER, où l'objectif est d'identifier et de classer des entités (par exemple, personne, organisation, date) dans une séquence de texte.
- Un modèle NER basé sur BERT est formé en prenant le vecteur de sortie de chaque jeton du transformateur et en l'introduisant dans une couche de classification. La couche prédit l'étiquette d'entité nommée pour chaque jeton, indiquant le type d'entité qu'il représente.
Comment tokeniser et encoder du texte à l'aide de BERT ?
Pour tokeniser et encoder du texte à l'aide de BERT, nous utiliserons la bibliothèque « transformer » en Python.
Commande pour installer les transformateurs :
!pip install transformers>
- Nous allons charger le tokenize BERT pré-entraîné avec un vocabulaire casé en utilisant BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode (texte) tokenise le texte saisi et le convertit en une séquence d'ID de jeton.
- print(ID de jeton :, encodage) imprime les ID de jeton obtenus après l'encodage.
- tokenizer.convert_ids_to_tokens (encodage) reconvertit les ID de jeton en jetons correspondants.
- print(Jetons :, jetons) imprime les jetons obtenus après conversion des ID de jeton
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Sortir:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> Le tokenizer.encode méthode ajoute le spécial [CLS] – classement et [SEP] – séparateur jetons au début et à la fin de la séquence codée.
Application du BERT
BERT est utilisé pour :
- Représentation du texte : BERT est utilisé pour générer des intégrations de mots ou une représentation de mots dans une phrase.
- Reconnaissance d'entité nommée (NER) : BERT peut être affiné pour les tâches de reconnaissance d'entités nommées, où l'objectif est d'identifier des entités telles que des noms de personnes, d'organisations, de lieux, etc., dans un texte donné.
- Classement du texte : BERT est largement utilisé pour les tâches de classification de texte, notamment l'analyse des sentiments, la détection du spam et la catégorisation des sujets. Il a démontré d’excellentes performances dans la compréhension et la classification du contexte des données textuelles.
- Systèmes de questions-réponses : BERT a été appliqué aux systèmes de questions-réponses, où le modèle est formé pour comprendre le contexte d'une question et fournir des réponses pertinentes. Ceci est particulièrement utile pour des tâches telles que la compréhension écrite.
- Traduction automatique: Les intégrations contextuelles de BERT peuvent être exploitées pour améliorer les systèmes de traduction automatique. Le modèle capture les nuances de langage qui sont cruciales pour une traduction précise.
- Résumé du texte : BERT peut être utilisé pour le résumé abstrait de textes, où le modèle génère des résumés concis et significatifs de textes plus longs en comprenant le contexte et la sémantique.
- IA conversationnelle : BERT est employé dans la création de systèmes d'IA conversationnelle, tels que des chatbots, des assistants virtuels et des systèmes de dialogue. Sa capacité à saisir le contexte le rend efficace pour comprendre et générer des réponses en langage naturel.
- Similitude sémantique : Les intégrations BERT peuvent être utilisées pour mesurer la similarité sémantique entre des phrases ou des documents. Ceci est précieux dans des tâches telles que la détection des doublons, l’identification des paraphrases et la récupération d’informations.
BERT contre GPT
Les différences entre BERT et GPT sont les suivantes :
| BERTE | Google Tag | |
|---|---|---|
| Architecture | BERT est conçu pour l'apprentissage des représentations bidirectionnelles. Il utilise un objectif de modèle de langage masqué, dans lequel il prédit les mots manquants dans une phrase en fonction du contexte gauche et droit. | GPT, quant à lui, est conçu pour la modélisation générative du langage. Il prédit le mot suivant dans une phrase en fonction du contexte précédent, en utilisant une approche autorégressive unidirectionnelle. |
| Objectifs de pré-formation | BERT est pré-entraîné à l'aide d'un objectif de modèle de langage masqué et de la prédiction de la phrase suivante. Il se concentre sur la capture du contexte bidirectionnel et la compréhension des relations entre les mots dans une phrase. | GPT est pré-entraîné pour prédire le mot suivant dans une phrase, ce qui encourage le modèle à apprendre une représentation cohérente du langage et à générer des séquences contextuellement pertinentes. |
| Compréhension du contexte | BERT est efficace pour les tâches qui nécessitent une compréhension approfondie du contexte et des relations au sein d'une phrase, telles que la classification de texte, la reconnaissance d'entités nommées et la réponse à des questions. | GPT est puissant pour générer un texte cohérent et contextuellement pertinent. Il est souvent utilisé dans les tâches créatives, les systèmes de dialogue et les tâches nécessitant la génération de séquences en langage naturel. |
| Types de tâches et cas d'utilisation
| Couramment utilisé dans des tâches telles que la classification de texte, la reconnaissance d'entités nommées, l'analyse des sentiments et la réponse aux questions. | Appliqué à des tâches telles que la génération de texte, les systèmes de dialogue, le résumé et l'écriture créative. |
| Mise au point ou apprentissage en quelques étapes | BERT est souvent affiné sur des tâches spécifiques en aval avec des données étiquetées pour adapter ses représentations pré-entraînées à la tâche à accomplir. | GPT est conçu pour effectuer un apprentissage en quelques étapes, où il peut se généraliser à de nouvelles tâches avec un minimum de données de formation spécifiques à la tâche. |
Vérifiez également :
- Classification des sentiments à l'aide de BERT
- Comment générer une intégration de mots à l'aide de BERT ?
- Modèle BART pour la complétion automatique de texte en PNL
- Classification des commentaires toxiques à l'aide de BERT
- Prédiction de la phrase suivante à l'aide de BERT
Foire aux questions (FAQ)
Q. À quoi sert BERT ?
BERT est utilisé pour effectuer des tâches PNL telles que la représentation de texte, la reconnaissance d'entités nommées, la classification de texte, les systèmes de questions-réponses, la traduction automatique, le résumé de texte, etc.
Q. Quels sont les avantages du modèle BERT ?
Le modèle linguistique BERT se distingue par sa pré-formation approfondie dans plusieurs langues, offrant une large couverture linguistique par rapport aux autres modèles. Cela rend BERT particulièrement avantageux pour les projets non basés sur l'anglais, car il fournit des représentations contextuelles robustes et une compréhension sémantique dans un large éventail de langues, améliorant ainsi sa polyvalence dans les applications multilingues.
Q. Comment BERT fonctionne-t-il pour l'analyse des sentiments ?
BERT excelle dans l'analyse des sentiments en tirant parti de son apprentissage de représentation bidirectionnelle pour capturer les nuances contextuelles, les significations sémantiques et les structures syntaxiques dans un texte donné. Cela permet à BERT de comprendre le sentiment exprimé dans une phrase en considérant les relations entre les mots, ce qui donne lieu à des résultats d'analyse des sentiments très efficaces.
centrer une image en CSS
Q. Google est-il basé sur BERT ?
BERTE et ClassementCerveau sont des composants de l’algorithme de recherche de Google qui traitent les requêtes et le contenu des pages Web afin de mieux comprendre et d’améliorer les résultats de recherche.