Les réseaux de neurones sont des modèles informatiques qui imitent les fonctions complexes du cerveau humain. Les réseaux de neurones sont constitués de nœuds ou de neurones interconnectés qui traitent et apprennent à partir des données, permettant ainsi des tâches telles que la reconnaissance de formes et la prise de décision dans l'apprentissage automatique. L'article explore davantage les réseaux de neurones, leur fonctionnement, leur architecture et bien plus encore.
Table des matières
- Évolution des réseaux de neurones
- Que sont les réseaux de neurones ?
- Comment fonctionnent les réseaux de neurones ?
- Apprentissage d'un réseau de neurones
- Types de réseaux de neurones
- Implémentation simple d'un réseau de neurones
Évolution des réseaux de neurones
Depuis les années 1940, de nombreuses avancées notables ont eu lieu dans le domaine des réseaux de neurones :
- Années 1940-1950 : premiers concepts
Les réseaux de neurones ont commencé avec l'introduction du premier modèle mathématique de neurones artificiels par McCulloch et Pitts. Mais les contraintes informatiques ont rendu les progrès difficiles.
- Années 1960-1970 : Perceptrons
Cette époque est définie par les travaux de Rosenblatt sur les perceptrons. Perceptrons sont des réseaux monocouches dont l'applicabilité était limitée aux problèmes qui pouvaient être résolus de manière linéaire séparément.
- Années 1980 : rétropropagation et connexionnisme
Réseau multicouche la formation a été rendue possible grâce à l’invention par Rumelhart, Hinton et Williams de la méthode de rétropropagation. En mettant l’accent sur l’apprentissage via des nœuds interconnectés, le connexionnisme a gagné en popularité.
- Années 1990 : boom et hiver
Avec des applications dans l’identification d’images, la finance et d’autres domaines, les réseaux de neurones ont connu un essor. La recherche sur les réseaux neuronaux a cependant connu un hiver en raison de coûts de calcul exorbitants et d'attentes exagérées.
- Années 2000 : résurgence et apprentissage profond
Des ensembles de données plus volumineux, des structures innovantes et une capacité de traitement améliorée ont stimulé un retour. L'apprentissage en profondeur a montré une efficacité étonnante dans un certain nombre de disciplines en utilisant de nombreuses couches.
- Années 2010 à aujourd’hui : domination du Deep Learning
Les réseaux de neurones convolutifs (CNN) et les réseaux de neurones récurrents (RNN), deux architectures d'apprentissage en profondeur, ont dominé l'apprentissage automatique. Leur puissance a été démontrée par des innovations dans les domaines des jeux, de la reconnaissance d’images et du traitement du langage naturel.
Que sont les réseaux de neurones ?
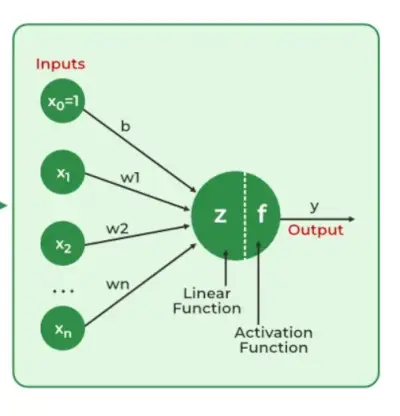
Les réseaux de neurones extraire des caractéristiques d’identification à partir de données, manquant de compréhension préprogrammée. Les composants du réseau comprennent des neurones, des connexions, des poids, des biais, des fonctions de propagation et une règle d'apprentissage. Les neurones reçoivent des entrées, régies par des seuils et des fonctions d'activation. Les connexions impliquent des poids et des biais régulant le transfert d’informations. L’apprentissage, l’ajustement des pondérations et des biais, se déroule en trois étapes : le calcul des entrées, la génération des sorties et le raffinement itératif améliorant la compétence du réseau dans diverses tâches.
Ceux-ci inclus:
- Le réseau neuronal est simulé par un nouvel environnement.
- Ensuite, les paramètres libres du réseau neuronal sont modifiés à la suite de cette simulation.
- Le réseau de neurones répond alors d'une nouvelle manière à l'environnement en raison des modifications de ses paramètres libres.
Importance des réseaux de neurones
La capacité des réseaux neuronaux à identifier des modèles, à résoudre des énigmes complexes et à s’adapter à un environnement changeant est essentielle. Leur capacité à apprendre des données a des effets considérables, allant de la révolution technologique comme traitement du langage naturel et les automobiles autonomes pour automatiser les processus de prise de décision et accroître l'efficacité dans de nombreux secteurs. Le développement de l’intelligence artificielle dépend largement des réseaux de neurones, qui stimulent également l’innovation et influencent l’orientation de la technologie.
Comment fonctionnent les réseaux de neurones ?
Comprenons avec un exemple le fonctionnement d'un réseau de neurones :
Considérez un réseau neuronal pour la classification des e-mails. La couche d'entrée prend en charge des fonctionnalités telles que le contenu des e-mails, les informations sur l'expéditeur et l'objet. Ces entrées, multipliées par des poids ajustés, traversent des couches cachées. Le réseau, grâce à la formation, apprend à reconnaître des modèles indiquant si un e-mail est du spam ou non. La couche de sortie, avec une fonction d'activation binaire, prédit si l'e-mail est du spam (1) ou non (0). Au fur et à mesure que le réseau affine ses pondérations de manière itérative par rétropropagation, il devient habile à faire la distinction entre le spam et les e-mails légitimes, démontrant ainsi le caractère pratique des réseaux de neurones dans des applications du monde réel comme le filtrage des e-mails.
Fonctionnement d'un réseau de neurones
Les réseaux neuronaux sont des systèmes complexes qui imitent certaines caractéristiques du fonctionnement du cerveau humain. Il est composé d'une couche d'entrée, d'une ou plusieurs couches cachées et d'une couche de sortie composée de couches de neurones artificiels couplés. Les deux étapes du processus de base sont appelées rétropropagation et propagation vers l'avant .
Propagation vers l'avant
- Couche d'entrée : Chaque entité de la couche d'entrée est représentée par un nœud sur le réseau, qui reçoit les données d'entrée.
- Poids et connexions : Le poids de chaque connexion neuronale indique la force de la connexion. Tout au long de l'entraînement, ces poids sont modifiés.
- Calques cachés : Chaque neurone de la couche cachée traite les entrées en les multipliant par des poids, en les additionnant, puis en les faisant passer par une fonction d'activation. Ce faisant, la non-linéarité est introduite, permettant au réseau de reconnaître des modèles complexes.
- Sortir: Le résultat final est produit en répétant le processus jusqu'à ce que la couche de sortie soit atteinte.
Rétropropagation
- Calcul des pertes : La sortie du réseau est évaluée par rapport aux valeurs réelles des objectifs et une fonction de perte est utilisée pour calculer la différence. Pour un problème de régression, le Erreur quadratique moyenne (MSE) est couramment utilisé comme fonction de coût.
Fonction de perte :
- Descente graduelle: La descente de gradient est ensuite utilisée par le réseau pour réduire la perte. Pour réduire l'imprécision, les poids sont modifiés en fonction de la dérivée de la perte par rapport à chaque poids.
- Ajustement des poids : Les poids sont ajustés à chaque connexion en appliquant ce processus itératif, ou rétropropagation , en arrière sur le réseau.
- Entraînement: Au cours de la formation avec différents échantillons de données, l'ensemble du processus de propagation vers l'avant, de calcul des pertes et de rétropropagation est effectué de manière itérative, permettant au réseau de s'adapter et d'apprendre des modèles à partir des données.
- Fonctions d'activation : La non-linéarité du modèle est introduite par des fonctions d'activation telles que unité linéaire rectifiée (ReLU) heures sigmoïde . Leur décision de déclencher ou non un neurone est basée sur l’ensemble des données pondérées.

Apprentissage d'un réseau de neurones
1. Apprendre avec l’apprentissage supervisé
Dans enseignement supervisé , le réseau de neurones est guidé par un enseignant qui a accès aux deux paires d'entrées-sorties. Le réseau crée des sorties basées sur des entrées sans tenir compte de l'environnement. En comparant ces sorties aux sorties souhaitées connues de l'enseignant, un signal d'erreur est généré. Afin de réduire les erreurs, les paramètres du réseau sont modifiés de manière itérative et s’arrêtent lorsque les performances sont à un niveau acceptable.
2. Apprendre avec un apprentissage non supervisé
Les variables de sortie équivalentes sont absentes dans apprentissage non supervisé . Son objectif principal est de comprendre la structure sous-jacente des données entrantes (X). Aucun instructeur n'est présent pour donner des conseils. La modélisation des modèles et des relations de données est plutôt le résultat escompté. Des mots comme régression et classification sont liés à l’apprentissage supervisé, tandis que l’apprentissage non supervisé est associé au regroupement et à l’association.
3. Apprendre avec l'apprentissage par renforcement
Grâce à l'interaction avec l'environnement et aux retours sous forme de récompenses ou de pénalités, le réseau acquiert des connaissances. Trouver une politique ou une stratégie qui optimise les récompenses cumulées au fil du temps est l’objectif du réseau. Ce type est fréquemment utilisé dans les applications de jeux et de prise de décision.
Types de réseaux de neurones
Il y a Sept types de réseaux de neurones pouvant être utilisés.
- Réseaux à action directe : UN réseau neuronal à action directe est une architecture simple de réseau neuronal artificiel dans laquelle les données se déplacent de l'entrée à la sortie dans une seule direction. Il comporte des couches d'entrée, cachées et de sortie ; les boucles de rétroaction sont absentes. Son architecture simple le rend approprié pour un certain nombre d'applications, telles que la régression et la reconnaissance de formes.
- Perceptron multicouche (MLP) : MLP est un type de réseau neuronal à action directe avec trois couches ou plus, dont une couche d'entrée, une ou plusieurs couches cachées et une couche de sortie. Il utilise des fonctions d'activation non linéaires.
- Réseau neuronal convolutif (CNN) : UN Réseau neuronal convolutif (CNN) est un réseau de neurones artificiels spécialisé conçu pour le traitement d’images. Il utilise des couches convolutives pour apprendre automatiquement les caractéristiques hiérarchiques des images d'entrée, permettant ainsi une reconnaissance et une classification efficaces des images. Les CNN ont révolutionné la vision par ordinateur et jouent un rôle essentiel dans des tâches telles que la détection d'objets et l'analyse d'images.
- Réseau neuronal récurrent (RNN) : Un type de réseau de neurones artificiels destiné au traitement séquentiel de données est appelé un Réseau neuronal récurrent (RNN). Il convient aux applications où les dépendances contextuelles sont critiques, telles que la prédiction de séries chronologiques et le traitement du langage naturel, car il utilise des boucles de rétroaction qui permettent aux informations de survivre au sein du réseau.
- Mémoire à long terme (LSTM) : LSTM est un type de RNN conçu pour surmonter le problème du gradient de disparition lors de la formation des RNN. Il utilise des cellules de mémoire et des portes pour lire, écrire et effacer de manière sélective des informations.
Implémentation simple d'un réseau de neurones
Python3
import> numpy as np> # array of any amount of numbers. n = m> X>=> np.array([[>1>,>2>,>3>],> >[>3>,>4>,>1>],> >[>2>,>5>,>3>]])> # multiplication> y>=> np.array([[.>5>, .>3>, .>2>]])> # transpose of y> y>=> y.T> # sigma value> sigm>=> 2> # find the delta> delt>=> np.random.random((>3>,>3>))>-> 1> for> j>in> range>(>100>):> > ># find matrix 1. 100 layers.> >m1>=> (y>-> (>1>/>(>1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt))))))>*>((>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))>*>(>1>->(>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))))> ># find matrix 2> >m2>=> m1.dot(delt.T)>*> ((>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> >*> (>1>->(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))))> ># find delta> >delt>=> delt>+> (>1>/>(>1> +> np.exp(>->(np.dot(X, sigm))))).T.dot(m1)> ># find sigma> >sigm>=> sigm>+> (X.T.dot(m2))> # print output from the matrix> print>(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> |
>
>
Sortir:
[[0.99999325 0.99999375 0.99999352] [0.99999988 0.99999989 0.99999988] [1. 1. 1. ]]>
Avantages des réseaux de neurones
Les réseaux de neurones sont largement utilisés dans de nombreuses applications différentes en raison de leurs nombreux avantages :
- Adaptabilité: Les réseaux de neurones sont utiles pour les activités où le lien entre les entrées et les sorties est complexe ou mal défini, car ils peuvent s'adapter à de nouvelles situations et apprendre des données.
- La reconnaissance de formes: Leur maîtrise de la reconnaissance de formes les rend efficaces dans des tâches telles que l'identification d'audio et d'images, le traitement du langage naturel et d'autres modèles de données complexes.
- Traitement parallèle : Étant donné que les réseaux de neurones sont par nature capables de traiter en parallèle, ils peuvent traiter de nombreuses tâches à la fois, ce qui accélère et améliore l'efficacité des calculs.
- Non-linéarité : Les réseaux de neurones sont capables de modéliser et de comprendre des relations complexes dans les données grâce aux fonctions d'activation non linéaires trouvées dans les neurones, qui surmontent les inconvénients des modèles linéaires.
Inconvénients des réseaux de neurones
Les réseaux de neurones, bien que puissants, ne sont pas sans inconvénients et difficultés :
- Intensité de calcul : La formation sur de grands réseaux neuronaux peut être un processus laborieux et exigeant en termes de calcul, qui nécessite beaucoup de puissance de calcul.
- Boite noire Nature : En tant que modèles de boîtes noires, les réseaux de neurones posent problème dans des applications importantes car il est difficile de comprendre comment ils prennent des décisions.
- Surapprentissage : Le surapprentissage est un phénomène dans lequel les réseaux de neurones mémorisent le matériel de formation plutôt que d'identifier des modèles dans les données. Même si les approches de régularisation contribuent à atténuer ce problème, le problème persiste.
- Besoin de grands ensembles de données : Pour une formation efficace, les réseaux de neurones ont souvent besoin d’ensembles de données importants et étiquetés ; sinon, leurs performances pourraient souffrir de données incomplètes ou faussées.
Foire aux questions (FAQ)
1. Qu'est-ce qu'un réseau de neurones ?
Un réseau de neurones est un système artificiel constitué de nœuds interconnectés (neurones) qui traitent les informations, calqué sur la structure du cerveau humain. Il est utilisé dans les tâches d'apprentissage automatique où des modèles sont extraits de données.
2. Comment fonctionne un réseau de neurones ?
Des couches de neurones connectés traitent les données dans les réseaux de neurones. Le réseau traite les données d'entrée, modifie les poids pendant l'entraînement et produit un résultat en fonction des modèles qu'il a découverts.
3. Quels sont les types courants d’architectures de réseaux neuronaux ?
Les réseaux de neurones feedforward, les réseaux de neurones récurrents (RNN), les réseaux de neurones convolutifs (CNN) et les réseaux de mémoire à long terme (LSTM) sont des exemples d'architectures courantes conçues chacune pour une tâche spécifique.
4. Quelle est la différence entre l'apprentissage supervisé et non supervisé dans les réseaux de neurones ?
Dans l'apprentissage supervisé, les données étiquetées sont utilisées pour entraîner un réseau neuronal afin qu'il puisse apprendre à mapper les entrées sur les sorties correspondantes. L'apprentissage non supervisé fonctionne avec des données non étiquetées et recherche des structures ou des modèles dans les données .
5. Comment les réseaux de neurones gèrent-ils les données séquentielles ?
Les boucles de rétroaction intégrées aux réseaux neuronaux récurrents (RNN) leur permettent de traiter des données séquentielles et, au fil du temps, de capturer les dépendances et le contexte.