- Redshift est un service d'entrepôt de données rapide et puissant, entièrement géré, à l'échelle du pétaoctet, dans le cloud.
- Les clients peuvent utiliser Redshift pour seulement 0,25 $ par heure, sans engagement ni frais initiaux, et évoluer jusqu'à un pétaoctet ou plus pour 1 000 $ par téraoctet et par an.
OLAP
OLAP est un Système de traitement d'analyse en ligne utilisé par le Redshift .
Exemple de transaction OLAP :
Supposons que nous souhaitions calculer le bénéfice net pour la région EMEA et Pacifique pour le produit radio numérique. Cela nécessite d'extraire un grand nombre d'enregistrements. Voici les enregistrements requis pour calculer un bénéfice net :
- Somme des radios vendues dans la région EMEA.
- Somme des radios vendues dans le Pacifique.
- Coût unitaire de la radio dans chaque région.
- Prix de vente de chaque radio
- Prix de vente - coût unitaire
Les requêtes complexes sont nécessaires pour récupérer les enregistrements indiqués ci-dessus. Les bases de données d'entreposage de données utilisent différents types d'architecture, à la fois du point de vue de la base de données et de la couche d'infrastructure.
Configuration du décalage rouge
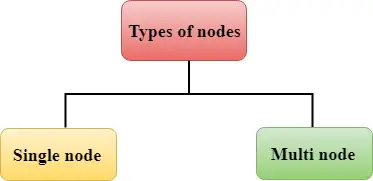
Redshift se compose de deux types de nœuds :
Nœud unique : Un seul nœud stocke jusqu'à 160 Go.
Multi-nœuds : Un multi-nœud est un nœud composé de plusieurs nœuds. Il est de deux types :
Il gère les connexions clients et reçoit les requêtes. Un nœud leader reçoit les requêtes des applications clientes, analyse les requêtes et développe les plans d'exécution. Il coordonne l'exécution parallèle de ces plans avec le nœud de calcul et combine les résultats intermédiaires de tous les nœuds, puis renvoie le résultat final à l'application client.
Un nœud de calcul exécute les plans d'exécution, puis les résultats intermédiaires sont envoyés au nœud leader pour agrégation avant d'être renvoyés à l'application client. Il peut contenir jusqu'à 128 nœuds de calcul.
Comprenons le concept de nœud leader et de nœuds de calcul à travers un exemple.
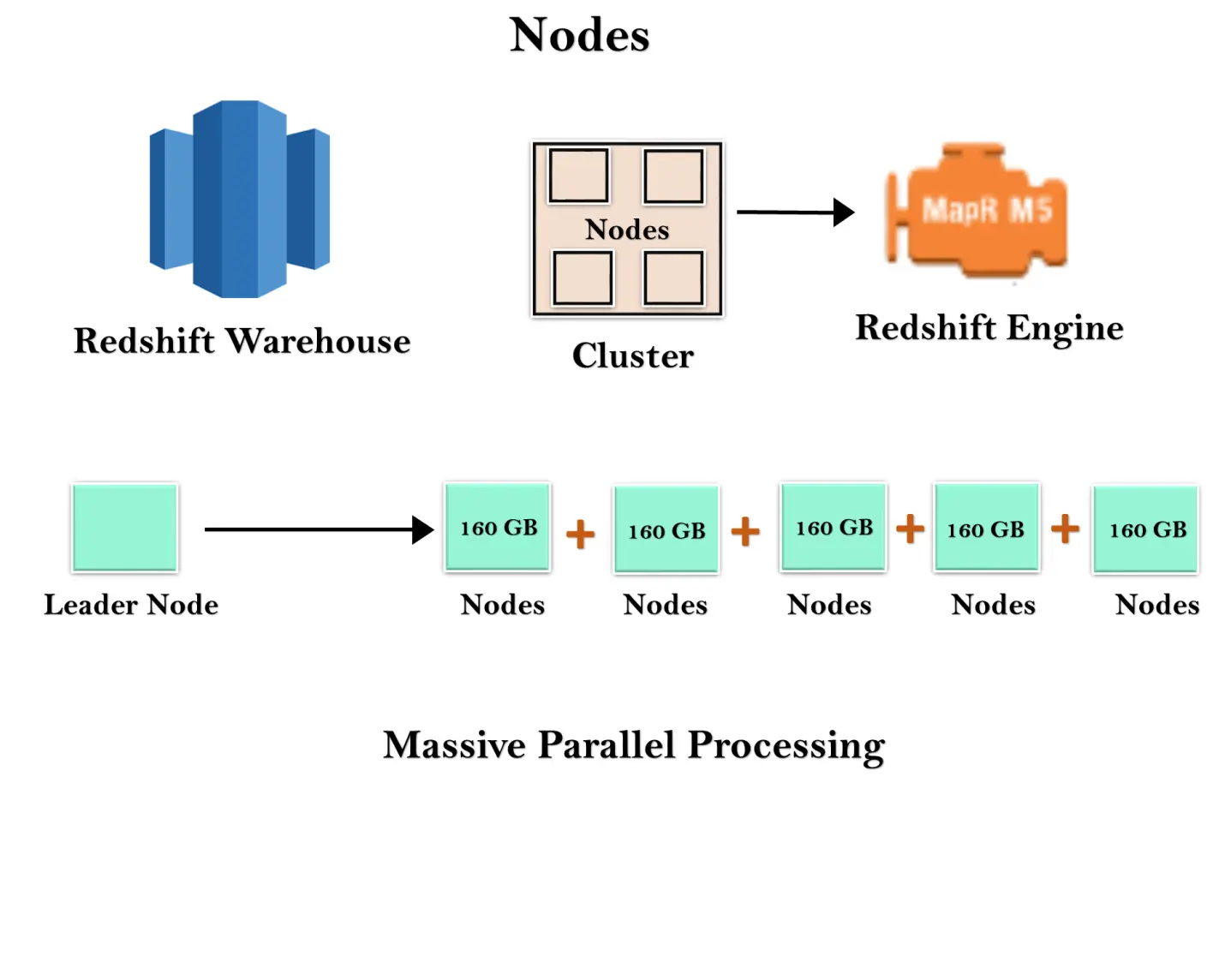
L'entrepôt Redshift est un ensemble de ressources informatiques appelées nœuds, et ces nœuds sont organisés en un groupe appelé cluster. Chaque cluster s'exécute dans un moteur Redshift qui contient une ou plusieurs bases de données.
Lorsque vous lancez une instance Redshift, elle démarre avec un seul nœud de taille 160 Go. Lorsque vous souhaitez vous développer, vous pouvez ajouter des nœuds supplémentaires pour profiter du traitement parallèle. Vous disposez d'un nœud leader qui gère les multiples nœuds. Le nœud leader gère la connexion client ainsi que les nœuds de calcul. Il stocke les données dans les nœuds de calcul et exécute la requête.
Pourquoi Redshift est 10 fois plus rapide
Redshift est 10 fois plus rapide pour les raisons suivantes :
Au lieu de stocker les données sous forme d'une série de lignes, Amazon Redshift organise les données par colonne. Les systèmes basés sur des lignes sont idéaux pour le traitement des transactions, tandis que les systèmes basés sur des colonnes sont idéaux pour l'entreposage et l'analyse de données, où les requêtes impliquent souvent des agrégats effectués sur de grands ensembles de données. Étant donné que seules les colonnes impliquées dans les requêtes sont traitées et que les données en colonnes sont stockées séquentiellement sur un support de stockage, les systèmes basés sur des colonnes nécessitent moins d'E/S, améliorant ainsi les performances des requêtes.
Les magasins de données en colonnes peuvent être bien plus compressés que les magasins de données basés sur les lignes, car les données similaires sont stockées séquentiellement sur le disque. Amazon Redshift utilise plusieurs techniques de compression et peut souvent obtenir une compression significative par rapport aux magasins de données relationnels traditionnels.
Amazon Redshift ne nécessite pas d'index ni de vues matérialisées. Il nécessite donc moins d'espace que les systèmes de bases de données relationnelles traditionnels. Lors du chargement de données dans une table vide, Amazon Redshift échantillonne automatiquement vos données et sélectionne la technique de compression la plus appropriée.
Amazon Redshift distribue automatiquement les données et charge la requête sur différents nœuds. Un Amazon Redshift facilite l'ajout de nouveaux nœuds à votre entrepôt de données, ce qui nous permet d'obtenir des performances de requête plus rapides à mesure que votre entrepôt de données se développe.
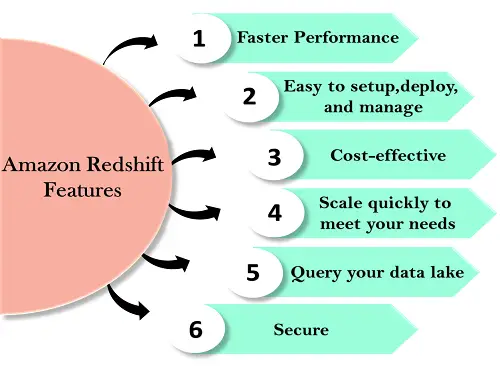
Fonctionnalités de Redshift
Les fonctionnalités de Redshift sont indiquées ci-dessous :
types d'arbres binaires
Redshift est simple à configurer et à utiliser. Vous pouvez déployer un nouvel entrepôt de données en quelques clics dans la console AWS, et Redshift provisionne automatiquement l'infrastructure pour vous. Dans AWS, toutes les tâches administratives sont automatisées, comme les sauvegardes et la réplication, vous devez vous concentrer sur vos données et non sur l'administration.
Redshift sauvegarde automatiquement vos données sur S3. Vous pouvez également répliquer les instantanés dans S3 dans une autre région pour toute reprise après sinistre.
Amazon Redshift est le service d'entrepôt de données le plus rentable, car vous ne devez payer que pour ce que vous utilisez.
Ses coûts commencent à 0,25 $ par heure, sans engagement ni frais initiaux, et peuvent atteindre 250 $ par téraoctet et par an.
Amazon Redshift est le seul service d'entrepôt de données qui propose une tarification à la demande sans frais initiaux, et propose également une tarification d'instance réservée qui permet d'économiser jusqu'à 75 % en offrant une durée de 1 à 3 ans.
Vous pouvez choisir l'un des deux nœuds pour optimiser le Redshift.
Un nœud de calcul dense peut créer des entrepôts de données hautes performances en utilisant des processeurs rapides, une grande quantité de RAM et des disques SSD.
Si vous souhaitez réduire les coûts, vous pouvez utiliser le nœud de stockage Dense. Il crée un entrepôt de données rentable en utilisant un disque dur plus grand.
Amazon Redshift augmente ou réduit automatiquement les nœuds en fonction des besoins. Avec seulement quelques clics dans la console AWS ou un seul appel d'API, vous pouvez facilement modifier le nombre de nœuds dans un entrepôt de données.
Il s'agit d'une fonctionnalité de Redshift qui vous permet d'exécuter des requêtes sur des exaoctets de données dans Amazon S3. Amazon S3 est un système de données sécurisé et économique permettant de stocker un nombre illimité de données dans un format ouvert.
C'est une fonctionnalité de Redshift qui signifie que plusieurs requêtes peuvent accéder aux mêmes données dans Amazon S3. Il vous permet d'exécuter des requêtes sur plusieurs nœuds, quelle que soit la complexité d'une requête ou la quantité de données.
Amazon Redshift est le seul entrepôt de données utilisé pour interroger le lac de données Amazon S3 sans charger de données. Cela offre de la flexibilité en stockant les données fréquemment consultées dans Redshift et les données non structurées ou rarement consultées dans Amazon S3.
Avec quelques réglages de paramètres, vous pouvez configurer Redshift pour qu'il utilise SSL pour sécuriser vos données. Vous pouvez également activer le cryptage, toutes les données écrites sur le disque seront cryptées.
Amazon Redshift fournit un stockage de données en colonnes, une compression et un traitement parallèle pour réduire la quantité d'E/S nécessaire à l'exécution des requêtes. Cela améliore les performances des requêtes.