UN Réseau neuronal convolutif (CNN) est un type d’architecture de réseau neuronal de Deep Learning couramment utilisé en vision par ordinateur. La vision par ordinateur est un domaine de l'intelligence artificielle qui permet à un ordinateur de comprendre et d'interpréter l'image ou les données visuelles.
En matière d'apprentissage automatique, Réseaux de neurones artificiels performer vraiment bien. Les réseaux de neurones sont utilisés dans divers ensembles de données tels que les images, l'audio et le texte. Différents types de réseaux de neurones sont utilisés à différentes fins, par exemple pour prédire la séquence de mots que nous utilisons Réseaux de neurones récurrents plus précisément un LSTM , de même pour la classification d'images, nous utilisons des réseaux de neurones à convolution. Dans ce blog, nous allons construire un élément de base pour CNN.
Dans un réseau de neurones classique, il existe trois types de couches :
- Couches d'entrée : C’est la couche dans laquelle nous apportons notre contribution à notre modèle. Le nombre de neurones dans cette couche est égal au nombre total de caractéristiques de nos données (nombre de pixels dans le cas d'une image).
- Couche cachée : L’entrée de la couche d’entrée est ensuite introduite dans la couche cachée. Il peut y avoir de nombreuses couches cachées en fonction de notre modèle et de la taille des données. Chaque couche cachée peut avoir un nombre différent de neurones qui est généralement supérieur au nombre de fonctionnalités. La sortie de chaque couche est calculée par multiplication matricielle de la sortie de la couche précédente avec les poids apprenables de cette couche, puis par l'ajout de biais apprenables suivi d'une fonction d'activation qui rend le réseau non linéaire.
- Couche de sortie : La sortie de la couche cachée est ensuite introduite dans une fonction logistique comme sigmoid ou softmax qui convertit la sortie de chaque classe en score de probabilité de chaque classe.
Les données sont introduites dans le modèle et la sortie de chaque couche est obtenue à partir de l'étape ci-dessus appelée rétroaction , nous calculons ensuite l'erreur à l'aide d'une fonction d'erreur, certaines fonctions d'erreur courantes sont l'entropie croisée, l'erreur de perte carrée, etc. La fonction d'erreur mesure les performances du réseau. Après cela, nous rétropropagons dans le modèle en calculant les dérivées. Cette étape est appelée Le réseau de neurones convolutifs (CNN) est la version étendue de réseaux de neurones artificiels (ANN) qui est principalement utilisé pour extraire l'entité de l'ensemble de données matricielles en forme de grille. Par exemple, des ensembles de données visuelles comme des images ou des vidéos où les modèles de données jouent un rôle important.
Architecture de CNN
Le réseau neuronal convolutif se compose de plusieurs couches telles que la couche d'entrée, la couche convolutive, la couche de pooling et les couches entièrement connectées.

Architecture CNN simple
tableau trié en java
La couche convolutive applique des filtres à l'image d'entrée pour extraire les caractéristiques, la couche Pooling sous-échantillonne l'image pour réduire les calculs et la couche entièrement connectée effectue la prédiction finale. Le réseau apprend les filtres optimaux par rétropropagation et descente de gradient.
Comment fonctionnent les couches convolutives
Les réseaux de neurones à convolution ou covnets sont des réseaux de neurones qui partagent leurs paramètres. Imaginez que vous avez une image. Il peut être représenté comme un cuboïde ayant sa longueur, sa largeur (dimension de l'image) et sa hauteur (c'est-à-dire que le canal car les images ont généralement des canaux rouge, vert et bleu).
Imaginez maintenant prendre un petit morceau de cette image et y exécuter un petit réseau de neurones, appelé filtre ou noyau, avec, par exemple, K sorties et les représenter verticalement. Faites maintenant glisser ce réseau neuronal sur toute l’image. Nous obtiendrons ainsi une autre image avec différentes largeurs, hauteurs et profondeurs. Au lieu des seuls canaux R, G et B, nous avons désormais plus de canaux mais une largeur et une hauteur moindres. Cette opération s'appelle Convolution . Si la taille du patch est la même que celle de l’image, il s’agira d’un réseau neuronal classique. Grâce à ce petit patch, nous avons moins de poids.
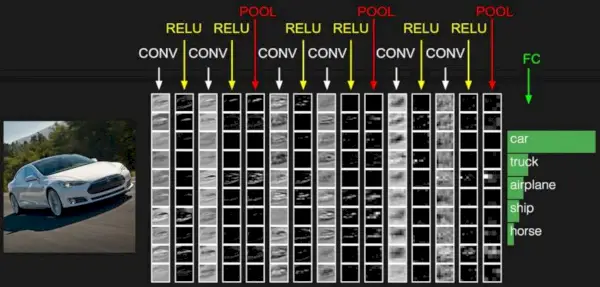
Source de l'image : Udacity d'apprentissage profond
Parlons maintenant d’un peu de mathématiques impliquées dans l’ensemble du processus de convolution.
- Les couches de convolution sont constituées d'un ensemble de filtres (ou noyaux) apprenables ayant de petites largeurs et hauteurs et la même profondeur que celle du volume d'entrée (3 si la couche d'entrée est une entrée d'image).
- Par exemple, si nous devons exécuter une convolution sur une image de dimensions 34x34x3. La taille possible des filtres peut être axax3, où « a » peut être quelque chose comme 3, 5 ou 7 mais plus petit par rapport à la dimension de l'image.
- Pendant le passage avant, nous faisons glisser chaque filtre sur tout le volume d'entrée, étape par étape, où chaque étape est appelée foulée (qui peut avoir une valeur de 2, 3 ou même 4 pour les images de grande dimension) et calcule le produit scalaire entre les poids du noyau et le patch du volume d'entrée.
- Au fur et à mesure que nous faisons glisser nos filtres, nous obtiendrons une sortie 2D pour chaque filtre et nous les empilerons en conséquence, nous obtiendrons un volume de sortie ayant une profondeur égale au nombre de filtres. Le réseau apprendra tous les filtres.
Couches utilisées pour créer des ConvNets
Une architecture complète de réseaux de neurones à convolution est également connue sous le nom de covnets. Un covnets est une séquence de couches, et chaque couche transforme un volume en un autre grâce à une fonction différentiable.
Types de couches : ensembles de données
Prenons un exemple en exécutant un covnets sur une image de dimension 32 x 32 x 3.
- Couches d'entrée : C’est la couche dans laquelle nous apportons notre contribution à notre modèle. Dans CNN, généralement, l'entrée sera une image ou une séquence d'images. Ce calque contient l'entrée brute de l'image avec une largeur de 32, une hauteur de 32 et une profondeur de 3.
- Couches convolutives : Il s'agit de la couche utilisée pour extraire l'entité de l'ensemble de données en entrée. Il applique un ensemble de filtres apprenables appelés noyaux aux images d'entrée. Les filtres/noyaux sont des matrices plus petites, généralement de forme 2×2, 3×3 ou 5×5. il glisse sur les données de l'image d'entrée et calcule le produit scalaire entre le poids du noyau et le patch d'image d'entrée correspondant. La sortie de cette couche est appelée cartes de caractéristiques. Supposons que nous utilisions un total de 12 filtres pour cette couche, nous obtiendrons un volume de sortie de dimension 32 x 32 x 12.
- Couche d'activation : En ajoutant une fonction d'activation à la sortie de la couche précédente, les couches d'activation ajoutent de la non-linéarité au réseau. il appliquera une fonction d'activation par élément à la sortie de la couche de convolution. Certaines fonctions d'activation courantes sont CV : max(0,x), De poisson , RELU qui fuit , etc. Le volume reste inchangé donc le volume de sortie aura les dimensions 32 x 32 x 12.
- Couche de pooling : Cette couche est périodiquement insérée dans les covnets et sa fonction principale est de réduire la taille du volume, ce qui accélère le calcul, réduit la mémoire et empêche également le surajustement. Deux types courants de couches de pooling sont mise en commun maximale et mise en commun moyenne . Si nous utilisons un pool max avec 2 x 2 filtres et une foulée 2, le volume résultant sera de dimension 16x16x12.
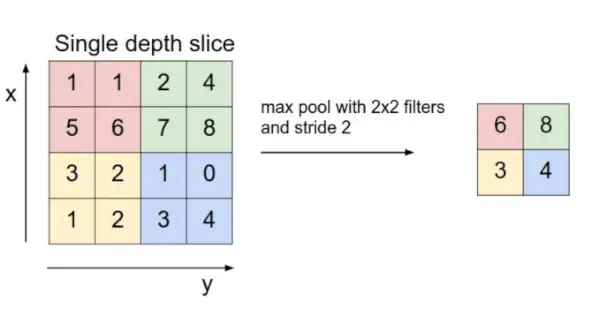
Source de l’image : cs231n.stanford.edu
- Aplanissement: Les cartes de caractéristiques résultantes sont aplaties en un vecteur unidimensionnel après les couches de convolution et de regroupement afin qu'elles puissent être transmises dans une couche entièrement liée pour la catégorisation ou la régression.
- Couches entièrement connectées : Il prend les entrées de la couche précédente et calcule la tâche finale de classification ou de régression.
Source de l’image : cs231n.stanford.edu
tri par insertion en Java
- Couche de sortie : La sortie des couches entièrement connectées est ensuite introduite dans une fonction logistique pour les tâches de classification comme sigmoïde ou softmax qui convertit la sortie de chaque classe en score de probabilité de chaque classe.
Exemple:
Considérons une image et appliquons l'opération de couche de convolution, de couche d'activation et de couche de pooling pour extraire la fonctionnalité intérieure.
Image d'entrée :
Image d'entrée
Étape:
- importer les bibliothèques nécessaires
- définir le paramètre
- définir le noyau
- Chargez l'image et tracez-la.
- Reformater l'image
- Appliquez l’opération de couche de convolution et tracez l’image de sortie.
- Appliquez l’opération de couche d’activation et tracez l’image de sortie.
- Appliquez l’opération de couche de pooling et tracez l’image de sortie.
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
multithread Java
>
>
Sortir :

Image originale en niveaux de gris
Sortir
Avantages des réseaux de neurones convolutifs (CNN) :
- Bon pour détecter des modèles et des caractéristiques dans les images, les vidéos et les signaux audio.
- Robuste à l’invariance de translation, de rotation et de mise à l’échelle.
- Formation de bout en bout, pas besoin d’extraction manuelle de fonctionnalités.
- Peut gérer de grandes quantités de données et atteindre une grande précision.
Inconvénients des réseaux de neurones convolutifs (CNN) :
- La formation est coûteuse en calcul et nécessite beaucoup de mémoire.
- Peut être sujet au surajustement si suffisamment de données ou si une régularisation appropriée n'est pas utilisée.
- Nécessite de grandes quantités de données étiquetées.
- L’interprétabilité est limitée, il est difficile de comprendre ce que le réseau a appris.
Foire aux questions (FAQ)
1: Qu'est-ce qu'un réseau de neurones convolutifs (CNN) ?
Un réseau neuronal convolutif (CNN) est un type de réseau neuronal d’apprentissage en profondeur bien adapté à l’analyse d’images et de vidéos. Les CNN utilisent une série de couches de convolution et de regroupement pour extraire des fonctionnalités d'images et de vidéos, puis utilisent ces fonctionnalités pour classer ou détecter des objets ou des scènes.
classe vs objet en Java
2 : Comment fonctionnent les CNN ?
Les CNN fonctionnent en appliquant une série de couches de convolution et de regroupement à une image ou une vidéo d'entrée. Les couches de convolution extraient les caractéristiques de l'entrée en faisant glisser un petit filtre, ou noyau, sur l'image ou la vidéo et en calculant le produit scalaire entre le filtre et l'entrée. Les couches de pooling sous-échantillonnent ensuite la sortie des couches de convolution pour réduire la dimensionnalité des données et les rendre plus efficaces sur le plan informatique.
3 : Quelles sont les fonctions d'activation courantes utilisées dans les CNN ?
Certaines fonctions d'activation courantes utilisées dans les CNN incluent :
- Unité linéaire rectifiée (ReLU) : ReLU est une fonction d'activation non saturante qui est efficace sur le plan informatique et facile à entraîner.
- Unité linéaire rectifiée avec fuite (Leaky ReLU) : Leaky ReLU est une variante de ReLU qui permet à une petite quantité de gradient négatif de circuler à travers le réseau. Cela peut aider à empêcher le réseau de mourir pendant la formation.
- Unité linéaire paramétrique rectifiée (PReLU) : PReLU est une généralisation de Leaky ReLU qui permet d'apprendre la pente du gradient négatif.
4 : Quel est le but d'utiliser plusieurs couches de convolution dans un CNN ?
L'utilisation de plusieurs couches de convolution dans un CNN permet au réseau d'apprendre des fonctionnalités de plus en plus complexes à partir de l'image ou de la vidéo d'entrée. Les premières couches de convolution apprennent des fonctionnalités simples, telles que les bords et les coins. Les couches de convolution plus profondes apprennent des fonctionnalités plus complexes, telles que des formes et des objets.
5 : Quelles sont les techniques de régularisation courantes utilisées dans les CNN ?
Des techniques de régularisation sont utilisées pour empêcher les CNN de surajuster les données de formation. Certaines techniques de régularisation courantes utilisées dans les CNN incluent :
- Abandon : L'abandon supprime aléatoirement les neurones du réseau pendant l'entraînement. Cela oblige le réseau à apprendre des fonctionnalités plus robustes qui ne dépendent d’aucun neurone unique.
- Régularisation L1 : la régularisation L1 régularise la valeur absolue des poids dans le réseau. Cela peut contribuer à réduire le nombre de poids et à rendre le réseau plus efficace.
- Régularisation L2 : la régularisation L2 régularise le carré des poids dans le réseau. Cela peut également contribuer à réduire le nombre de poids et à rendre le réseau plus efficace.
6 : Quelle est la différence entre une couche de convolution et une couche de pooling ?
Une couche de convolution extrait les caractéristiques d'une image ou d'une vidéo d'entrée, tandis qu'une couche de regroupement sous-échantillonne la sortie des couches de convolution. Les couches de convolution utilisent une série de filtres pour extraire les fonctionnalités, tandis que les couches de pooling utilisent diverses techniques pour sous-échantillonner les données, telles que le pooling maximum et le pooling moyen.