Un curseur dans SQL Server est un d objet atabase qui nous permet de récupérer chaque ligne à la fois et de manipuler ses données . Un curseur n'est rien de plus qu'un pointeur vers une ligne. Il est toujours utilisé conjointement avec une instruction SELECT. Il s'agit généralement d'un ensemble de SQL logique qui parcourt un nombre prédéterminé de lignes une par une. Une illustration simple du curseur est lorsque nous disposons d'une base de données étendue de dossiers de travailleurs et que nous souhaitons calculer le salaire de chaque travailleur après déduction des impôts et des congés.
Le serveur SQL le but du curseur est de mettre à jour les données ligne par ligne, de les modifier ou d'effectuer des calculs qui ne sont pas possibles lorsque nous récupérons tous les enregistrements en même temps . Il est également utile pour effectuer des tâches administratives telles que les sauvegardes de bases de données SQL Server dans un ordre séquentiel. Les curseurs sont principalement utilisés dans les processus de développement, DBA et ETL.
Cet article explique tout sur le curseur SQL Server, comme le cycle de vie du curseur, pourquoi et quand le curseur est utilisé, comment implémenter les curseurs, ses limites et comment remplacer un curseur.
Cycle de vie du curseur
Nous pouvons décrire le cycle de vie d'un curseur dans le cinq sections différentes comme suit:
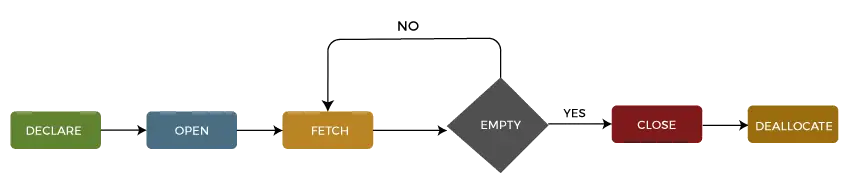
1 : Déclarer le curseur
La première étape consiste à déclarer le curseur à l'aide de l'instruction SQL ci-dessous :
fonction de sous-chaîne Java
DECLARE cursor_name CURSOR FOR select_statement;
Nous pouvons déclarer un curseur en spécifiant son nom avec le type de données CURSOR après le mot-clé DECLARE. Ensuite, nous écrirons l'instruction SELECT qui définit la sortie du curseur.
2 : Ouvrir le curseur
C'est une deuxième étape dans laquelle nous ouvrons le curseur pour stocker les données récupérées de l'ensemble de résultats. Nous pouvons le faire en utilisant l'instruction SQL ci-dessous :
OPEN cursor_name;
3 : Récupérer le curseur
Il s'agit d'une troisième étape dans laquelle les lignes peuvent être récupérées une par une ou dans un bloc pour effectuer des manipulations de données telles que des opérations d'insertion, de mise à jour et de suppression sur la ligne actuellement active dans le curseur. Nous pouvons le faire en utilisant l'instruction SQL ci-dessous :
FETCH NEXT FROM cursor INTO variable_list;
Nous pouvons également utiliser le @@FETCHSTATUS, fonction dans SQL Server pour obtenir l’état du curseur d’instruction FETCH le plus récent exécuté sur le curseur. Le ALLER CHERCHER L'instruction a réussi lorsque @@FETCHSTATUS ne donne aucune sortie. Le ALORS QUE L'instruction peut être utilisée pour récupérer tous les enregistrements du curseur. Le code suivant l'explique plus clairement :
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4 : Fermer le curseur
C'est une quatrième étape dans laquelle le curseur doit être fermé une fois que nous avons fini de travailler avec un curseur. Nous pouvons le faire en utilisant l'instruction SQL ci-dessous :
CLOSE cursor_name;
5 : Désallouer le curseur
C'est la cinquième et dernière étape dans laquelle nous effacerons la définition du curseur et libérerons toutes les ressources système associées au curseur. Nous pouvons le faire en utilisant l'instruction SQL ci-dessous :
DEALLOCATE cursor_name;
Utilisations du curseur SQL Server
Nous savons que les systèmes de gestion de bases de données relationnelles, notamment SQL Server, sont excellents dans la gestion des données sur un ensemble de lignes appelés jeux de résultats. Par exemple , nous avons une table table_produit qui contient les descriptions des produits. Si nous voulons mettre à jour le prix du produit, puis le ci-dessous ' MISE À JOUR' la requête mettra à jour tous les enregistrements qui correspondent à la condition dans le ' OÙ' clause:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Parfois, l’application doit traiter les lignes de manière unique, c’est-à-dire ligne par ligne plutôt que l’ensemble des résultats en une seule fois. Nous pouvons effectuer ce processus en utilisant des curseurs dans SQL Server. Avant d'utiliser le curseur, nous devons savoir que les curseurs ont de très mauvaises performances, il doit donc toujours être utilisé uniquement lorsqu'il n'y a pas d'option autre que le curseur.
Le curseur utilise la même technique que nous utilisons des boucles comme FOREACH, FOR, WHILE, DO WHILE pour parcourir un objet à la fois dans tous les langages de programmation. Par conséquent, il pourrait être choisi car il applique la même logique que le processus de bouclage du langage de programmation.
Types de curseurs dans SQL Server
Voici les différents types de curseurs dans SQL Server répertoriés ci-dessous :
- Curseurs statiques
- Curseurs dynamiques
- Curseurs avant uniquement
- Curseurs de jeu de touches

Curseurs statiques
Le jeu de résultats affiché par le curseur statique est toujours le même que lors de la première ouverture du curseur. Puisque le curseur statique stockera le résultat dans tempdb , ils sont toujours lecture seulement . Nous pouvons utiliser le curseur statique pour avancer et reculer. Contrairement aux autres curseurs, il est plus lent et consomme plus de mémoire. Par conséquent, nous ne pouvons l'utiliser que lorsque le défilement est nécessaire et que les autres curseurs ne conviennent pas.
Ce curseur affiche les lignes qui ont été supprimées de la base de données après son ouverture. Un curseur statique ne représente aucune opération INSERT, UPDATE ou DELETE (sauf si le curseur est fermé et rouvert).
Curseurs dynamiques
Les curseurs dynamiques sont opposés aux curseurs statiques qui nous permettent d'effectuer les opérations de mise à jour, de suppression et d'insertion des données lorsque le curseur est ouvert. C'est défilable par défaut . Il peut détecter toutes les modifications apportées aux lignes, à l'ordre et aux valeurs dans le jeu de résultats, que les modifications se produisent à l'intérieur ou à l'extérieur du curseur. En dehors du curseur, nous ne pouvons pas voir les mises à jour tant qu'elles ne sont pas validées.
Curseurs avant uniquement
Il s'agit du type de curseur par défaut et le plus rapide parmi tous les curseurs. On l'appelle un curseur avant uniquement car il avance uniquement dans l'ensemble de résultats . Ce curseur ne prend pas en charge le défilement. Il ne peut récupérer que les lignes du début à la fin du jeu de résultats. Il nous permet d'effectuer des opérations d'insertion, de mise à jour et de suppression. Ici, l'effet des opérations d'insertion, de mise à jour et de suppression effectuées par l'utilisateur et affectant les lignes du jeu de résultats est visible lorsque les lignes sont récupérées à partir du curseur. Lorsque la ligne a été récupérée, nous ne pouvons pas voir les modifications apportées aux lignes via le curseur.
Les curseurs avant uniquement sont classés en trois types :
- Jeu de clés Forward_Only
- Forward_Only Statique
- Avance rapide

Curseurs pilotés par jeu de clés
Cette fonctionnalité de curseur se situe entre un curseur statique et un curseur dynamique concernant sa capacité à détecter les changements. Il ne peut pas toujours détecter les changements dans l’appartenance et l’ordre du jeu de résultats comme un curseur statique. Il peut détecter les changements dans les valeurs des lignes du jeu de résultats comme un curseur dynamique. Cela ne peut que passer du premier au dernier et du dernier à la première ligne . L'ordre et l'adhésion sont fixés à chaque ouverture de ce curseur.
Il est exploité par un ensemble d'identifiants uniques identiques aux clés du jeu de clés. Le jeu de clés est déterminé par toutes les lignes qui qualifiaient l'instruction SELECT lors de la première ouverture du curseur. Il peut également détecter toute modification apportée à la source de données, qui prend en charge les opérations de mise à jour et de suppression. Il est déroulant par défaut.
Implémentation de l'exemple
Implémentons l'exemple de curseur dans le serveur SQL. Nous pouvons le faire en créant d'abord une table nommée ' client ' en utilisant la déclaration ci-dessous :
saisir une chaîne en java
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Ensuite, nous insérerons des valeurs dans le tableau. Nous pouvons exécuter l'instruction ci-dessous pour ajouter des données dans une table :
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Nous pouvons vérifier les données en exécutant le SÉLECTIONNER déclaration:
SELECT * FROM customer;
Après avoir exécuté la requête, nous pouvons voir la sortie ci-dessous où nous avons huit rangées dans le tableau :

Maintenant, nous allons créer un curseur pour afficher les enregistrements clients. Les extraits de code ci-dessous expliquent toutes les étapes de la déclaration ou de la création du curseur en rassemblant le tout :
pente indéfinie
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Après avoir exécuté un curseur, nous obtiendrons le résultat ci-dessous :

Limites du curseur SQL Server
Un curseur a certaines limitations, de sorte qu'il ne doit toujours être utilisé que lorsqu'il n'y a pas d'option autre que le curseur. Ces limitations sont :
- Le curseur consomme des ressources réseau en exigeant un aller-retour réseau à chaque fois qu'il récupère un enregistrement.
- Un curseur est un ensemble de pointeurs résidant en mémoire, ce qui signifie qu'il utilise de la mémoire que d'autres processus pourraient utiliser sur notre machine.
- Il impose des verrous sur une partie de la table ou sur la table entière lors du traitement des données.
- Les performances et la vitesse du curseur sont plus lentes car ils mettent à jour les enregistrements de la table une ligne à la fois.
- Les curseurs sont plus rapides que les boucles while, mais ils ont plus de temps système.
- Le nombre de lignes et de colonnes introduites dans le curseur est un autre aspect qui affecte la vitesse du curseur. Il fait référence au temps nécessaire pour ouvrir votre curseur et exécuter une instruction fetch.
Comment pouvons-nous éviter les curseurs ?
La tâche principale des curseurs est de parcourir le tableau ligne par ligne. Le moyen le plus simple d’éviter les curseurs est indiqué ci-dessous :
Utiliser la boucle while SQL
Le moyen le plus simple d'éviter l'utilisation d'un curseur est d'utiliser une boucle while qui permet d'insérer un jeu de résultats dans la table temporaire.
Fonctions définies par l'utilisateur
Parfois, des curseurs sont utilisés pour calculer l’ensemble de lignes résultant. Nous pouvons y parvenir en utilisant une fonction définie par l'utilisateur qui répond aux exigences.
Utiliser les jointures
Join traite uniquement les colonnes qui remplissent la condition spécifiée et réduit ainsi les lignes de code qui offrent des performances plus rapides que les curseurs au cas où des enregistrements volumineux devraient être traités.