Les feuilles Excel sont très instinctives et conviviales, ce qui les rend idéales pour manipuler de grands ensembles de données, même pour les personnes moins techniques. Si vous recherchez des endroits pour apprendre à manipuler et automatiser des éléments dans des fichiers Excel à l'aide de Python , cherchez pas plus loin. Vous êtes au bon endroit.
Dans cet article, vous apprendrez à utiliser Pandas travailler avec des feuilles de calcul Excel. Dans cet article, nous découvrirons :
- Lire Fichier Excel utiliser Pandas en Python
- Installation et importation de Pandas
- Lire plusieurs feuilles Excel à l'aide de Pandas
- Application de différentes fonctions Pandas
Lire un fichier Excel à l'aide de Pandas en Python
Installation de Pandas
Pour installer Pandas en Python, nous pouvons utiliser la commande suivante dans l'invite de commande :
un tableau en java
pip install pandas>
Pour installer Pandas dans Anaconda, nous pouvons utiliser la commande suivante dans Anaconda Terminal :
conda install pandas>
Importer des pandas
Tout d'abord, nous devons importer le module Pandas, ce qui peut être fait en exécutant la commande :
Python3
import> pandas as pd> |
>
>
Fichier d'entrée : Supposons que le fichier Excel ressemble à ceci
Feuille 1 :

Feuille 1
Feuille 2 :
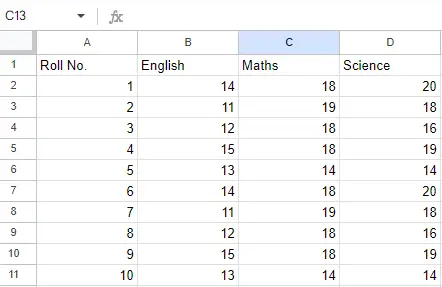
Feuille 2
Nous pouvons maintenant importer le fichier Excel à l'aide de la fonction read_excel dans Pandas pour lire le fichier Excel à l'aide de Pandas en Python. La deuxième instruction lit les données d'Excel et les stocke dans un cadre de données pandas qui est représenté par la variable newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Sortir:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Chargement de plusieurs feuilles à l'aide de la méthode Concat()
S'il y a plusieurs feuilles dans le classeur Excel, la commande importera les données de la première feuille. Pour créer un bloc de données avec toutes les feuilles du classeur, la méthode la plus simple consiste à créer différents blocs de données séparément, puis à les concaténer. La méthode read_excel prend les arguments sheet_name et index_col où l'on peut spécifier la feuille dont le cadre doit être constitué et index_col spécifie la colonne de titre, comme indiqué ci-dessous :
Exemple:
La troisième instruction concatène les deux feuilles. Maintenant, pour vérifier l'ensemble du bloc de données, nous pouvons simplement exécuter la commande suivante :
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Sortir:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Méthodes Head() et Tail() dans Pandas
Pour afficher 5 colonnes du haut et du bas du bloc de données, nous pouvons exécuter la commande. Ce tête() et queue() La méthode prend également les arguments sous forme de nombres pour le nombre de colonnes à afficher.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Sortir:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Méthode Forme()
Le Méthode forme() peut être utilisé pour afficher le nombre de lignes et de colonnes dans le bloc de données comme suit :
Python3
newData.shape> |
>
>
Sortir:
comparer aux chaînes en java
(20, 3)>
Méthode Sort_values() dans Pandas
Si une colonne contient des données numériques, nous pouvons trier cette colonne en utilisant le valeurs_de tri() méthode chez les pandas comme suit :
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Supposons maintenant que nous voulions les 5 premières valeurs de la colonne triée, nous pouvons utiliser la méthode head() ici :
Python3
sorted_column.head(>5>)> |
>
>
Sortir:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Nous pouvons le faire avec n'importe quelle colonne numérique du bloc de données, comme indiqué ci-dessous :
Python3
newData[>'Maths'>].head()> |
>
>
Sortir:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Méthode Pandas Describe()
Supposons maintenant que nos données soient principalement numériques. Nous pouvons obtenir des informations statistiques telles que la moyenne, le maximum, le minimum, etc. sur la trame de données en utilisant le décrire() méthode comme indiqué ci-dessous :
Python3
newData.describe()> |
>
>
Sortir:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Cela peut également être fait séparément pour toutes les colonnes numériques à l'aide de la commande suivante :
Python3
newData[>'English'>].mean()> |
>
>
Sortir:
14.3>
D'autres informations statistiques peuvent également être calculées à l'aide des méthodes respectives. Comme dans Excel, des formules peuvent également être appliquées et des colonnes calculées peuvent être créées comme suit :
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
codes d'erreur Linux
>
>
Sortir:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Après avoir opéré sur les données du bloc de données, nous pouvons réexporter les données vers un fichier Excel en utilisant la méthode to_excel. Pour cela, nous devons spécifier un fichier Excel de sortie dans lequel les données transformées doivent être écrites, comme indiqué ci-dessous :
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Sortir:
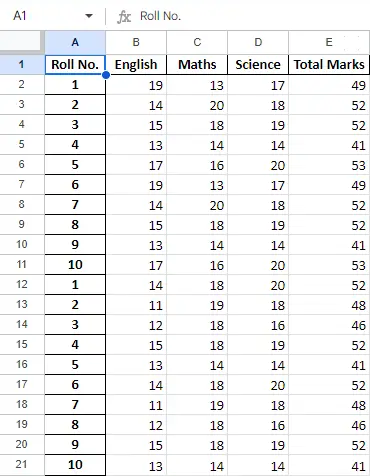
Feuille finale