Conception orientée objet a commencé dès l’invention des ordinateurs. La programmation était là et les approches de programmation sont entrées en scène. La programmation consiste essentiellement à donner certaines instructions à l'ordinateur.
Au début de l’ère informatique, la programmation se limitait généralement à la programmation en langage machine. Le langage machine désigne les ensembles d’instructions spécifiques à une machine ou à un processeur particulier, qui se présentent sous la forme de 0 et de 1. Ce sont des séquences de bits (0100110…). Mais il est assez difficile d’écrire un programme ou de développer un logiciel en langage machine.
Il est en fait impossible de développer des logiciels utilisés dans les scénarios actuels avec des séquences de bits. C’est la principale raison pour laquelle les programmeurs sont passés à la prochaine génération de langages de programmation, développant des langages d’assemblage suffisamment proches de la langue anglaise pour être facilement compris. Ces langages d'assemblage étaient utilisés dans les microprocesseurs. Avec l’invention du microprocesseur, les langages assembleurs ont prospéré et ont dominé l’industrie, mais cela n’a pas suffi. Encore une fois, les programmeurs ont proposé quelque chose de nouveau, à savoir une programmation structurée et procédurale.
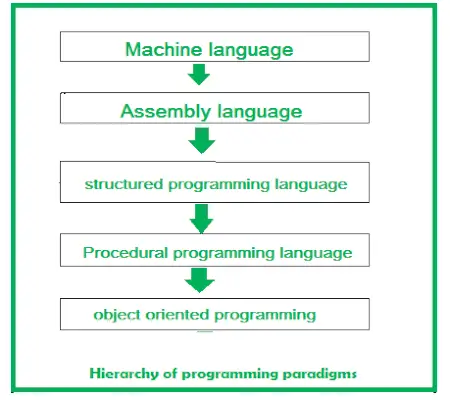
Programmation structurée –
Le principe de base de l’approche de programmation structurée est de diviser un programme en fonctions et modules. L'utilisation de modules et de fonctions rend le programme plus compréhensible et lisible. Cela permet d'écrire un code plus propre et de garder le contrôle sur les fonctions et les modules. Cette approche donne de l'importance aux fonctions plutôt qu'aux données. Il se concentre sur le développement de grandes applications logicielles, par exemple, le C a été utilisé pour le développement de systèmes d'exploitation modernes. Les langages de programmation : PASCAL (introduit par Niklaus Wirth) et C (introduit par Dennis Ritchie) suivent cette approche.
Approche de programmation procédurale –
Cette approche est également connue sous le nom d’approche descendante. Dans cette approche, un programme est divisé en fonctions qui effectuent des tâches spécifiques. Cette approche est principalement utilisée pour les applications de taille moyenne. Les données sont globales et toutes les fonctions peuvent accéder aux données globales. L’inconvénient fondamental de l’approche de programmation procédurale est que les données ne sont pas sécurisées car elles sont globales et accessibles par n’importe quelle fonction. Le flux de contrôle du programme est obtenu via des appels de fonction et des instructions goto. Les langages de programmation : FORTRAN (développé par IBM) et COBOL (développé par le Dr Grace Murray Hopper) suivent cette approche.
Ces constructions de programmation ont été développées à la fin des années 1970 et dans les années 1980. Il y avait encore quelques problèmes avec ces langages, même s'ils répondaient aux critères de programmes, logiciels, etc. bien structurés. Ils n'étaient pas aussi structurés que les exigences de l'époque. Ils semblent trop généralisés et ne correspondent pas aux applications en temps réel.
Pour résoudre ce type de problèmes, la POO, une approche orientée objet, a été développée comme solution.

L’approche de programmation orientée objet (POO) –
Le concept POO a été essentiellement conçu pour surmonter les inconvénients des méthodologies de programmation ci-dessus, qui n'étaient pas si proches des applications du monde réel. La demande a augmenté, mais les méthodes conventionnelles ont néanmoins été utilisées. Cette nouvelle approche a apporté une révolution dans le domaine de la méthodologie de programmation.
La programmation orientée objet (POO) n'est rien d'autre que ce qui permet d'écrire des programmes à l'aide de certaines classes et objets temps réel. On peut dire que cette approche est très proche du monde réel et de ses applications car l'état et le comportement de ces classes et objets sont presque les mêmes que ceux des objets du monde réel.
Approfondissons les concepts généraux de la POO, qui sont donnés ci-dessous :
Que sont la classe et l'objet ?
C'est le concept de base de la POO ; un concept étendu de la structure utilisée en C. Il s'agit d'un type de données abstrait et défini par l'utilisateur. Il se compose de plusieurs variables et fonctions. L'objectif principal de la classe est de stocker des données et des informations. Les membres d'une classe définissent le comportement de la classe. Une classe est le modèle de l’objet, mais on peut aussi dire que l’implémentation de la classe est l’objet. La classe n’est pas visible au monde, mais l’objet l’est.
RPC
Class car> {> >int> car_id;> >char> colour[4];> >float> engine_no;> >double> distance;> > >void> distance_travelled();> >float> petrol_used();> >char> music_player();> >void> display();> }> |
>
>
Ici, la classe car a les propriétés car_id, colour, engine_no et distance. Elle ressemble à la voiture du monde réel qui a les mêmes spécifications, qui peut être déclarée publique (visible par tous en dehors de la classe), protégée et privée (visible par personne). Il existe également des méthodes telles que distance_travelled(), Petrol_used(), music_player() et display(). Dans le code ci-dessous, la voiture est une classe et c1 est un objet de la voiture.
RPC
#include> using> namespace> std;> > class> car {> public>:> >int> car_id;> >double> distance;> > >void> distance_travelled();> > >void> display(>int> a,>int> b)> >{> >cout <<>'car id is= '> << a <<>'
distance travelled = '> << b + 5;> >}> };> > int> main()> {> >car c1;>// Declare c1 of type car> >c1.car_id = 321;> >c1.distance = 12;> >c1.display(321, 12);> > >return> 0;> }> |
>
>
Abstraction de données -
L'abstraction fait référence à l'acte de représenter des caractéristiques importantes et spéciales sans inclure les détails de base ou les explications sur cette caractéristique. L'abstraction des données simplifie la conception des bases de données.

- Niveau physique :
Il décrit comment les enregistrements sont stockés, qui sont souvent cachés à l'utilisateur. Il peut être décrit par l’expression bloc de stockage.
Niveau logique :
Il décrit les données stockées dans la base de données et les relations entre les données. Les programmeurs travaillent généralement à ce niveau car ils connaissent les fonctions nécessaires pour maintenir les relations entre les données.
Niveau d'affichage :
Les programmes d'application masquent les détails des types de données et des informations à des fins de sécurité. Ce niveau est généralement implémenté à l'aide de l'interface graphique et les détails destinés à l'utilisateur sont affichés.
Encapsulation –
L'encapsulation est l'un des concepts fondamentaux de la programmation orientée objet (POO). Il décrit l'idée d'encapsuler les données et les méthodes qui fonctionnent sur les données dans une seule unité, par exemple une classe en Java. Ce concept est souvent utilisé pour masquer de l’extérieur la représentation de l’état interne d’un objet.
Héritage -
L'héritage est la capacité d'une classe à hériter des capacités ou des propriétés d'une autre classe, appelée classe parent. Lorsque nous écrivons une classe, nous héritons des propriétés des autres classes. Ainsi, lorsque nous créons une classe, nous n’avons pas besoin d’écrire encore et encore toutes les propriétés et fonctions, car celles-ci peuvent être héritées d’une autre classe qui la possède. L'héritage permet à l'utilisateur de réutiliser le code autant que possible et de réduire sa redondance.

Java
import> java.io.*;> > class> GFG {> >public> static> void> main(String[] args)> >{> >System.out.println(>'GfG!'>);> > >Dog dog =>new> Dog();> >dog.name =>'Bull dog'>;> >dog.color =>'Brown'>;> >dog.bark();> >dog.run();> > >Cat cat =>new> Cat();> >cat.name =>'Rag doll'>;> >cat.pattern =>'White and slight brownish'>;> >cat.meow();> >cat.run();> > >Animal animal =>new> Animal();> > >animal.name =>'My favourite pets'>;> > >animal.run();> >}> }> > class> Animal {> >String name;> >public> void> run()> >{> > >System.out.println(>'Animal is running!'>);> >}> }> > class> Dog>extends> Animal {> > /// the class dog is the child and animal is the parent> > >String color;> >public> void> bark()> >{> >System.out.println(name +>' Wooh ! Wooh !'> >+>'I am of colour '> + color);> >}> }> > class> Cat>extends> Animal {> > >String pattern;> > >public> void> meow()> >{> >System.out.println(name +>' Meow ! Meow !'> >+>'I am of colour '> + pattern);> >}> }> |
âge de Hrithik Roshan
>
>
C++
#include> #include> using> namespace> std;> > class> Animal {> public>:> >string name;> >void> run(){> >cout<<>'Animal is running!'>< } }; class Dog : public Animal { /// the class dog is the child and animal is the parent public: string color; void bark(){ cout<' Wooh ! Wooh !' <<'I am of colour '< } }; class Cat : public Animal { public: string pattern; void meow(){ cout<' Meow ! Meow !'<<'I am of colour '< } }; int main(){ cout<<'GFG'< Dog dog; dog.name = 'Bull dog'; dog.color = 'Brown'; dog.bark(); dog.run(); Cat cat; cat.name = 'Rag doll'; cat.pattern = 'White and slight brownish'; cat.meow(); cat.run(); Animal animal; animal.name = 'My favourite pets'; animal.run(); return 0; //code contributed by Sanket Gode. }> |
>
>Sortir
GfG! Bull dog Wooh ! Wooh !I am of colour Brown Animal is running! Rag doll Meow ! Meow !I am of colour White and slight brownish Animal is running! Animal is running!>
Polymorphisme –
Le polymorphisme est la capacité des données à être traitées sous plusieurs formes. Il permet d’accomplir la même tâche de différentes manières. Cela consiste à surcharger et à remplacer la méthode, c'est-à-dire à écrire la méthode une fois et à effectuer un certain nombre de tâches en utilisant le même nom de méthode.

RPC
#include> using> namespace> std;> > void> output(>float>);> void> output(>int>);> void> output(>int>,>float>);> > int> main()> {> >cout <<>'
GfG!
'>;> >int> a = 23;> >float> b = 2.3;> > >output(a);> >output(b);> >output(a, b);> > >return> 0;> }> > void> output(>int> var)> {>// same function name but different task> >cout <<>'Integer number: '> << var << endl;> }> > void> output(>float> var)> {>// same function name but different task> >cout <<>'Float number: '> << var << endl;> }> > void> output(>int> var1,>float> var2)> {>// same function name but different task> >cout <<>'Integer number: '> << var1;> >cout <<>' and float number:'> << var2;> }> |
>
>
Quelques points importants à savoir sur la POO :
- La POO traite les données comme un élément critique.
- L'accent est mis sur les données plutôt que sur la procédure.
- Décomposition du problème en modules plus simples.
- Ne permet pas aux données de circuler librement dans l'ensemble du système, c'est-à-dire un flux de contrôle localisé.
- Les données sont protégées des fonctions externes.
Avantages des POO –
- Il modélise très bien le monde réel.
- Avec la POO, les programmes sont faciles à comprendre et à maintenir.
- La POO offre la réutilisabilité du code. Les classes déjà créées peuvent être réutilisées sans avoir à les réécrire.
- La POO facilite le développement rapide de programmes où le développement parallèle de classes est possible.
- Avec la POO, les programmes sont plus faciles à tester, à gérer et à déboguer.
Inconvénients de la POO –
- Avec la POO, les classes ont parfois tendance à être trop généralisées.
- Les relations entre classes deviennent parfois superficielles.
- La conception POO est délicate et nécessite des connaissances appropriées. En outre, il faut planifier et concevoir correctement la programmation POO.
- Pour programmer avec la POO, le programmeur a besoin de compétences appropriées telles que la conception, la programmation et la réflexion en termes d'objets et de classes, etc.