Comme nous le savons, l'algorithme d'apprentissage automatique supervisé peut être largement classé en algorithmes de régression et de classification. Dans les algorithmes de régression, nous avons prédit le résultat pour des valeurs continues, mais pour prédire les valeurs catégorielles, nous avons besoin d'algorithmes de classification.
Qu'est-ce que l'algorithme de classification ?
L'algorithme de classification est une technique d'apprentissage supervisé qui est utilisée pour identifier la catégorie de nouvelles observations sur la base de données d'entraînement. Dans Classification, un programme apprend à partir de l'ensemble de données ou des observations donnés, puis classe les nouvelles observations en un certain nombre de classes ou de groupes. Tel que, Oui ou Non, 0 ou 1, Spam ou Pas Spam, chat ou chien, etc. Les classes peuvent être appelées cibles/étiquettes ou catégories.
bash lire le fichier
Contrairement à la régression, la variable de sortie de la classification est une catégorie et non une valeur, telle que « Vert ou Bleu », « fruit ou animal », etc. Puisque l'algorithme de classification est une technique d'apprentissage supervisé, il prend donc des données d'entrée étiquetées, qui signifie qu'il contient une entrée avec la sortie correspondante.
Dans l'algorithme de classification, une fonction de sortie discrète (y) est mappée à une variable d'entrée (x).
y=f(x), where y = categorical output
Le meilleur exemple d'algorithme de classification ML est Détecteur de spam par courrier électronique .
L'objectif principal de l'algorithme de classification est d'identifier la catégorie d'un ensemble de données donné, et ces algorithmes sont principalement utilisés pour prédire la sortie des données catégorielles.
Les algorithmes de classification peuvent être mieux compris à l'aide du diagramme ci-dessous. Dans le diagramme ci-dessous, il existe deux classes, la classe A et la classe B. Ces classes ont des fonctionnalités similaires les unes aux autres et différentes des autres classes.
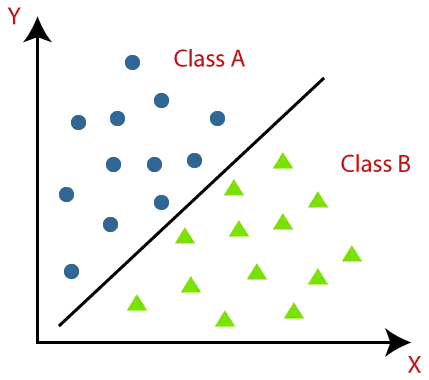
L'algorithme qui implémente la classification sur un ensemble de données est appelé classificateur. Il existe deux types de classements :
Exemples: OUI ou NON, MÂLE ou FEMME, SPAM ou NON SPAM, CHAT ou CHIEN, etc.
Exemple: Classifications des types de cultures, Classification des types de musique.
Apprenants en problèmes de classification :
Dans les problèmes de classification, il existe deux types d’apprenants :
Exemple: Algorithme K-NN, raisonnement basé sur des cas
Types d'algorithmes de classification ML :
Les algorithmes de classification peuvent être divisés en deux catégories principales :
- Régression logistique
- Machines à vecteurs de support
- K-Voisins les plus proches
- SVM du noyau
- Na�ve Bayes
- Classification de l'arbre de décision
- Classification aléatoire des forêts
Remarque : nous apprendrons les algorithmes ci-dessus dans les chapitres suivants.
Évaluation d'un modèle de classification :
Une fois notre modèle complété, il est nécessaire d’évaluer ses performances ; soit il s'agit d'un modèle de classification ou de régression. Ainsi, pour évaluer un modèle de classification, nous disposons des méthodes suivantes :
1. Perte de journal ou perte d'entropie croisée :
- Il est utilisé pour évaluer les performances d'un classificateur, dont la sortie est une valeur de probabilité comprise entre 0 et 1.
- Pour un bon modèle de classification binaire, la valeur de la perte log doit être proche de 0.
- La valeur de la perte logarithmique augmente si la valeur prévue s'écarte de la valeur réelle.
- La perte logarithmique inférieure représente la plus grande précision du modèle.
- Pour la classification binaire, l'entropie croisée peut être calculée comme suit :
?(ylog(p)+(1?y)log(1?p))
Où y = sortie réelle, p = sortie prévue.
2. Matrice de confusion :
- La matrice de confusion nous fournit une matrice/tableau en sortie et décrit les performances du modèle.
- Elle est également connue sous le nom de matrice d’erreur.
- La matrice est constituée de résultats de prédictions sous une forme résumée, qui présente un nombre total de prédictions correctes et de prédictions incorrectes. La matrice ressemble au tableau ci-dessous :
| Réel positif | Réel négatif | |
|---|---|---|
| Prédit positif | Vrai positif | Faux positif |
| Négatif prévu | Faux négatif | Vrai négatif |

3. Courbe AUC-ROC :
les bases de Java
- La courbe ROC signifie Courbe des caractéristiques de fonctionnement du récepteur et AUC signifie Aire sous la courbe .
- Il s'agit d'un graphique qui montre les performances du modèle de classification à différents seuils.
- Pour visualiser les performances du modèle de classification multi-classes, nous utilisons la courbe AUC-ROC.
- La courbe ROC est tracée avec TPR et FPR, où TPR (True Positive Rate) sur l'axe Y et FPR (False Positive Rate) sur l'axe X.
Cas d'utilisation des algorithmes de classification
Les algorithmes de classification peuvent être utilisés à différents endroits. Vous trouverez ci-dessous quelques cas d’utilisation courants des algorithmes de classification :
- Détection du spam par courrier électronique
- Reconnaissance de la parole
- Identifications des cellules tumorales cancéreuses.
- Classification des drogues
- Identification biométrique, etc.