La recherche non informée est une classe d’algorithmes de recherche à usage général qui fonctionnent par force brute. Les algorithmes de recherche non informés ne disposent pas d'informations supplémentaires sur l'état ou l'espace de recherche autres que la façon de parcourir l'arborescence, c'est pourquoi on parle également de recherche aveugle.
Voici les différents types d’algorithmes de recherche non informés :
1. Recherche en largeur :
- La recherche en largeur est la stratégie de recherche la plus courante pour parcourir un arbre ou un graphique. Cet algorithme effectue une recherche en largeur dans un arbre ou un graphique, c'est pourquoi on l'appelle recherche en largeur d'abord.
- L'algorithme BFS commence la recherche à partir du nœud racine de l'arborescence et développe tous les nœuds successeurs du niveau actuel avant de passer aux nœuds du niveau suivant.
- L'algorithme de recherche en largeur d'abord est un exemple d'algorithme de recherche de graphe général.
- Recherche en largeur d'abord mise en œuvre à l'aide de la structure de données de file d'attente FIFO.
Avantages :
- BFS fournira une solution si une solution existe.
- S'il existe plusieurs solutions pour un problème donné, alors BFS fournira la solution minimale qui nécessite le moins d'étapes.
Désavantages:
- Cela nécessite beaucoup de mémoire puisque chaque niveau de l’arborescence doit être enregistré en mémoire pour pouvoir développer le niveau suivant.
- BFS a besoin de beaucoup de temps si la solution est éloignée du nœud racine.
Exemple:
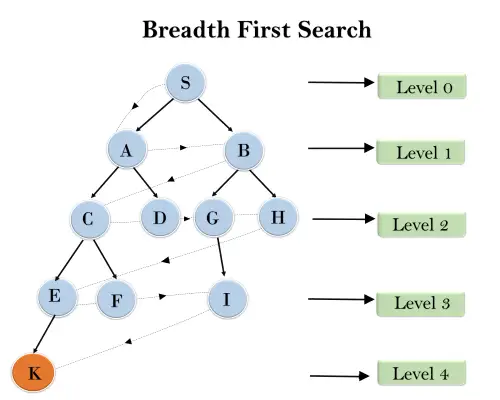
Dans l'arborescence ci-dessous, nous avons montré le parcours de l'arbre à l'aide de l'algorithme BFS du nœud racine S au nœud objectif K. L'algorithme de recherche BFS traverse en couches, il suivra donc le chemin indiqué par la flèche en pointillé, et le le chemin parcouru sera :
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
Complexité temporelle : La complexité temporelle de l'algorithme BFS peut être obtenue par le nombre de nœuds traversés dans BFS jusqu'au nœud le moins profond. Où d = profondeur de la solution la moins profonde et b est un nœud à chaque état.
T (b) = 1+b2+b3+.......+ bd= O (bd)
Complexité spatiale : La complexité spatiale de l'algorithme BFS est donnée par la taille de la mémoire de la frontière qui est O(bd).
Complétude : BFS est terminé, ce qui signifie que si le nœud objectif le moins profond se trouve à une profondeur finie, alors BFS trouvera une solution.
comparer les chaînes java
Optimalité : BFS est optimal si le coût du chemin est une fonction non décroissante de la profondeur du nœud.
2. Recherche en profondeur d'abord
- La recherche en profondeur est un algorithme récursif permettant de parcourir une structure de données arborescente ou graphique.
- C'est ce qu'on appelle la recherche en profondeur d'abord car elle part du nœud racine et suit chaque chemin jusqu'à son nœud le plus profond avant de passer au chemin suivant.
- DFS utilise une structure de données de pile pour sa mise en œuvre.
- Le processus de l'algorithme DFS est similaire à celui de l'algorithme BFS.
Remarque : Le backtracking est une technique algorithmique permettant de trouver toutes les solutions possibles en utilisant la récursivité.
Avantage:
- DFS nécessite très moins de mémoire car il lui suffit de stocker une pile de nœuds sur le chemin allant du nœud racine au nœud actuel.
- Il faut moins de temps pour atteindre le nœud objectif que l'algorithme BFS (s'il traverse dans le bon chemin).
Désavantage:
- Il est possible que de nombreux États se reproduisent sans cesse, et il n’y a aucune garantie de trouver une solution.
- L'algorithme DFS effectue une recherche approfondie et parfois il peut aller dans la boucle infinie.
Exemple:
Dans l'arbre de recherche ci-dessous, nous avons montré le flux de recherche en profondeur d'abord, et il suivra l'ordre suivant :
Nœud racine ---> Nœud gauche ----> Nœud droit.
Il commencera la recherche à partir du nœud racine S et traversera A, puis B, puis D et E, après avoir traversé E, il reviendra en arrière dans l'arbre car E n'a pas d'autre successeur et le nœud objectif n'est toujours pas trouvé. Après avoir fait marche arrière, il traversera le nœud C puis G, et ici il se terminera lorsqu'il a trouvé le nœud objectif.

Complétude : L'algorithme de recherche DFS est complet dans un espace d'états fini car il développera chaque nœud dans un arbre de recherche limité.
Complexité temporelle : La complexité temporelle de DFS sera équivalente au nœud traversé par l'algorithme. Il est donné par :
T(n)= 1+n2+n3+.........+ nm=O(nm)
Où, m = profondeur maximale de n'importe quel nœud et cela peut être beaucoup plus grand que d (profondeur de solution la plus faible)
Complexité spatiale : L'algorithme DFS doit stocker un seul chemin à partir du nœud racine, donc la complexité spatiale de DFS est équivalente à la taille de l'ensemble de franges, qui est À propos .
Optimale : L'algorithme de recherche DFS n'est pas optimal, car il peut générer un grand nombre d'étapes ou un coût élevé pour atteindre le nœud objectif.
3. Algorithme de recherche limité en profondeur :
Un algorithme de recherche limité en profondeur est similaire à une recherche en profondeur d'abord avec une limite prédéterminée. La recherche limitée en profondeur peut résoudre l'inconvénient du chemin infini dans la recherche en profondeur d'abord. Dans cet algorithme, le nœud à la limite de profondeur sera traité comme s'il n'avait plus de nœuds successeurs.
La recherche limitée en profondeur peut être terminée avec deux conditions d'échec :
- Valeur d'échec standard : elle indique que le problème n'a pas de solution.
- Valeur de rupture de coupure : elle ne définit aucune solution au problème dans une limite de profondeur donnée.
Avantages :
La recherche limitée en profondeur est efficace en termes de mémoire.
Désavantages:
- La recherche limitée en profondeur présente également l’inconvénient d’être incomplète.
- Cela peut ne pas être optimal si le problème a plusieurs solutions.
Exemple:

Complétude : L'algorithme de recherche DLS est terminé si la solution est au-dessus de la limite de profondeur.
Complexité temporelle : La complexité temporelle de l'algorithme DLS est O(bℓ) .
Complexité spatiale : La complexité spatiale de l'algorithme DLS est O (b�ℓ) .
Optimale : La recherche limitée en profondeur peut être considérée comme un cas particulier de DFS, et elle n'est pas non plus optimale même si ℓ>d.
4. Algorithme de recherche à coût uniforme :
La recherche à coût uniforme est un algorithme de recherche utilisé pour parcourir un arbre ou un graphique pondéré. Cet algorithme entre en jeu lorsqu’un coût différent est disponible pour chaque arête. L’objectif principal de la recherche à coût uniforme est de trouver un chemin vers le nœud d’objectif ayant le coût cumulé le plus bas. La recherche à coût uniforme développe les nœuds en fonction de leurs coûts de chemin depuis le nœud racine. Il peut être utilisé pour résoudre n’importe quel graphique/arbre où le coût optimal est recherché. Un algorithme de recherche à coût uniforme est implémenté par la file d'attente prioritaire. Il donne la priorité maximale au coût cumulé le plus bas. La recherche de coût uniforme est équivalente à l’algorithme BFS si le coût du chemin de toutes les arêtes est le même.
Avantages :
- La recherche de coûts uniformes est optimale car, à chaque état, le chemin le moins coûteux est choisi.
Désavantages:
- Il ne se soucie pas du nombre d'étapes impliquées dans la recherche et ne se soucie que du coût du chemin. C’est pour cette raison que cet algorithme peut être bloqué dans une boucle infinie.
Exemple:

Complétude :
La recherche à coût uniforme est terminée, par exemple s'il existe une solution, UCS la trouvera.
maman kulkarni
Complexité temporelle :
Soit C* est le coût de la solution optimale , et e est chaque étape pour se rapprocher du nœud objectif. Alors le nombre d’étapes est = C*/ε+1. Ici, nous avons pris +1, car nous partons de l'état 0 et terminons par C*/ε.
Par conséquent, la complexité temporelle dans le pire des cas de la recherche à coût uniforme est O(b1 + [C*/e])/ .
Complexité spatiale :
La même logique s'applique à la complexité spatiale, donc la complexité spatiale dans le pire des cas de recherche à coût uniforme est O(b1 + [C*/e]) .
Optimale :
La recherche à coût uniforme est toujours optimale car elle sélectionne uniquement le chemin ayant le coût de chemin le plus bas.
5. Recherche itérative d'approfondissement en profondeur d'abord :
L'algorithme d'approfondissement itératif est une combinaison d'algorithmes DFS et BFS. Cet algorithme de recherche découvre la meilleure limite de profondeur et le fait en augmentant progressivement la limite jusqu'à ce qu'un objectif soit trouvé.
Cet algorithme effectue une recherche en profondeur d'abord jusqu'à une certaine « limite de profondeur », et continue d'augmenter la limite de profondeur après chaque itération jusqu'à ce que le nœud objectif soit trouvé.
Cet algorithme de recherche combine les avantages de la recherche rapide en largeur et l'efficacité de la mémoire de la recherche en profondeur.
L'algorithme de recherche itérative est utile pour une recherche non informée lorsque l'espace de recherche est grand et que la profondeur du nœud objectif est inconnue.
Avantages :
- Il combine les avantages des algorithmes de recherche BFS et DFS en termes de recherche rapide et d'efficacité de la mémoire.
Désavantages:
- Le principal inconvénient d’IDDFS est qu’il répète tout le travail de la phase précédente.
Exemple:
La structure arborescente suivante montre la recherche itérative d’approfondissement en profondeur d’abord. L'algorithme IDDFS effectue diverses itérations jusqu'à ce qu'il ne trouve pas le nœud objectif. L’itération effectuée par l’algorithme est donnée par :

1ère itération -----> A
2ème itération ----> A, B, C
3ème itération ------>A, B, D, E, C, F, G
4ème itération ------>A, B, D, H, I, E, C, F, K, G
Lors de la quatrième itération, l’algorithme trouvera le nœud objectif.
Complétude :
Cet algorithme est complet si le facteur de branchement est fini.
Complexité temporelle :
longueur de chaîne java
Supposons que b soit le facteur de branchement et que la profondeur soit d, alors la complexité temporelle dans le pire des cas est O(bd) .
Complexité spatiale :
La complexité spatiale d’IDDFS sera O(bd) .
Optimale :
L’algorithme IDDFS est optimal si le coût du chemin est une fonction non décroissante de la profondeur du nœud.
6. Algorithme de recherche bidirectionnel :
L'algorithme de recherche bidirectionnel exécute deux recherches simultanées, l'une depuis l'état initial appelée recherche avant et l'autre à partir du nœud d'objectif appelée recherche en arrière, pour trouver le nœud d'objectif. La recherche bidirectionnelle remplace un seul graphe de recherche par deux petits sous-graphes dans lesquels l'un commence la recherche à partir d'un sommet initial et l'autre à partir du sommet objectif. La recherche s'arrête lorsque ces deux graphiques se croisent.
La recherche bidirectionnelle peut utiliser des techniques de recherche telles que BFS, DFS, DLS, etc.
Avantages :
- La recherche bidirectionnelle est rapide.
- La recherche bidirectionnelle nécessite moins de mémoire
Désavantages:
- La mise en œuvre de l’arbre de recherche bidirectionnel est difficile.
Exemple:
Dans l'arborescence de recherche ci-dessous, un algorithme de recherche bidirectionnel est appliqué. Cet algorithme divise un graphique/arbre en deux sous-graphiques. Il commence à traverser à partir du nœud 1 dans le sens avant et à partir du nœud objectif 16 dans le sens arrière.
L'algorithme se termine au nœud 9 où deux recherches se rencontrent.

Complétude : La recherche bidirectionnelle est complète si nous utilisons BFS dans les deux recherches.
Complexité temporelle : La complexité temporelle de la recherche bidirectionnelle à l'aide de BFS est O(bd) .
Complexité spatiale : La complexité spatiale de la recherche bidirectionnelle est O(bd) .
Optimale : La recherche bidirectionnelle est optimale.