Dans le système d'exploitation, nous devions donner l'entrée au CPU, et le CPU exécute les instructions et donne enfin la sortie. Mais cette approche posait un problème. Dans une situation normale, nous devons gérer de nombreux processus, et nous savons que le temps nécessaire à l'opération d'E/S est très important par rapport au temps nécessaire au CPU pour l'exécution des instructions. Ainsi, dans l'ancienne approche, un processus donnerait l'entrée à l'aide d'un périphérique d'entrée, et pendant ce temps, le processeur était dans un état inactif.
algorithme connu
Ensuite, le CPU exécute l'instruction et la sortie est à nouveau donnée à un périphérique de sortie, et à ce moment-là, le CPU est également dans un état inactif. Après avoir affiché la sortie, le processus suivant commence son exécution. Ainsi, la plupart du temps, le processeur est inactif, ce qui est la pire condition que l'on puisse rencontrer dans les systèmes d'exploitation. Ici, le concept de Spooling entre en jeu.
Qu'est-ce que la mise en file d'attente
La mise en file d'attente est un processus dans lequel les données sont temporairement conservées pour être utilisées et exécutées par un appareil, un programme ou un système. Les données sont envoyées et stockées en mémoire ou dans un autre stockage volatile jusqu'à ce que le programme ou l'ordinateur en demande l'exécution.
SPOOL est un acronyme pour opérations périphériques simultanées en ligne . Généralement, le spool est conservé dans la mémoire physique de l'ordinateur, dans les tampons ou sur les interruptions spécifiques au périphérique d'E/S. La bobine est traitée par ordre croissant, fonctionnant sur la base d'un algorithme FIFO (premier entré, premier sorti).
La mise en file d'attente consiste à placer les données de diverses tâches d'E/S dans un tampon. Ce tampon est une zone spéciale de la mémoire ou du disque dur accessible aux périphériques d'E/S. Un système d'exploitation effectue les activités suivantes liées à l'environnement distribué :
- Gère la mise en file d'attente des données des périphériques d'E/S, car les périphériques ont des taux d'accès aux données différents.
- Maintient le tampon de mise en file d'attente, qui fournit une station d'attente où les données peuvent reposer pendant que le périphérique le plus lent rattrape son retard.
- Maintient le calcul parallèle en raison du processus de mise en file d'attente, car un ordinateur peut effectuer des E/S dans un ordre parallèle. Il devient possible que l'ordinateur lise des données sur une bande, les écrive sur un disque et les écrive sur une imprimante à bande pendant qu'il effectue sa tâche informatique.
Comment fonctionne la mise en file d'attente dans le système d'exploitation
Dans un système d'exploitation, la mise en file d'attente fonctionne selon les étapes suivantes, telles que :
- La mise en file d'attente implique la création d'un tampon appelé SPOOL, qui est utilisé pour suspendre les tâches et les données jusqu'à ce que le périphérique dans lequel le SPOOL est créé soit prêt à utiliser et à exécuter cette tâche ou à exploiter les données.
- Lorsqu'un périphérique plus rapide envoie des données à un périphérique plus lent pour effectuer une opération, il utilise toute mémoire secondaire connectée comme tampon SPOOL. Ces données sont conservées dans le SPOOL jusqu'à ce que l'appareil le plus lent soit prêt à fonctionner sur ces données. Lorsque le périphérique le plus lent est prêt, les données du SPOOL sont chargées dans la mémoire principale pour les opérations requises.
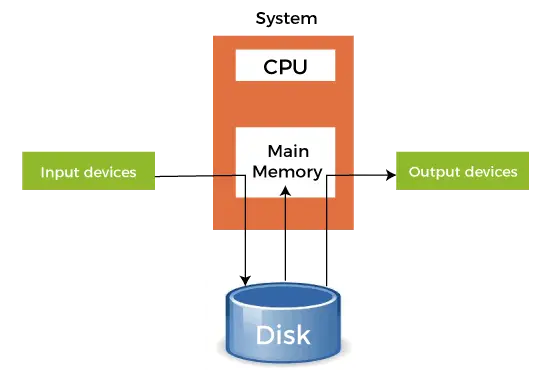
- Le spooling considère la totalité de la mémoire secondaire comme un énorme tampon pouvant stocker de nombreux travaux et données pour de nombreuses opérations. L'avantage du Spooling est qu'il peut créer une file d'attente de tâches qui s'exécutent dans l'ordre FIFO pour exécuter les tâches une par une.
- Un appareil peut se connecter à de nombreux périphériques d'entrée, ce qui peut nécessiter certaines opérations sur leurs données. Ainsi, tous ces périphériques d'entrée peuvent placer leurs données dans la mémoire secondaire (SPOOL), qui peuvent ensuite être exécutées une par une par le périphérique. Cela garantira que le processeur ne soit pas inactif à tout moment. Nous pouvons donc dire que le spooling est une combinaison de mise en mémoire tampon et de mise en file d'attente.
- Une fois que le processeur a généré une sortie, cette sortie est d'abord enregistrée dans la mémoire principale. Cette sortie est transférée vers la mémoire secondaire depuis la mémoire principale, et à partir de là, la sortie est envoyée aux périphériques de sortie respectifs.

Exemple de mise en file d'attente
Le plus grand exemple de Spooling est impression . Les documents à imprimer sont stockés dans le SPOOL puis ajoutés à la file d'attente pour l'impression. Pendant ce temps, de nombreux processus peuvent effectuer leurs opérations et utiliser le processeur sans attendre pendant que l'imprimante exécute le processus d'impression sur les documents un par un.

De nombreuses fonctionnalités peuvent également être ajoutées au processus d'impression Spooling, comme la définition de priorités ou la notification lorsque le processus d'impression est terminé ou la sélection des différents types de papier sur lesquels imprimer selon le choix de l'utilisateur.
Avantages de la mise en file d'attente
Voici les avantages suivants de la mise en file d'attente dans un système d'exploitation, tels que :
réseau et types de réseau
- Le nombre de périphériques d'E/S ou d'opérations n'a pas d'importance. De nombreux périphériques d'E/S peuvent fonctionner ensemble simultanément sans aucune interférence ni perturbation les uns des autres.
- Lors du spooling, il n'y a aucune interaction entre les périphériques d'E/S et le CPU. Cela signifie que le processeur n'a pas besoin d'attendre que les opérations d'E/S aient lieu. De telles opérations mettent beaucoup de temps à s'exécuter, le processeur n'attendra donc pas qu'elles se terminent.
- Le processeur à l’état inactif n’est pas considéré comme très efficace. La plupart des protocoles sont créés pour utiliser efficacement le processeur en un minimum de temps. En spooling, le processeur reste occupé la plupart du temps et ne passe à l'état inactif que lorsque la file d'attente est épuisée. Ainsi, toutes les tâches sont ajoutées à la file d’attente et le processeur terminera toutes ces tâches puis passera à l’état inactif.
- Il permet aux applications de s'exécuter à la vitesse du processeur tout en faisant fonctionner les périphériques d'E/S à leur vitesse maximale respective.
Inconvénients de la mise en file d'attente
Dans un système d'exploitation, la mise en file d'attente présente les inconvénients suivants, tels que :
- La mise en file d'attente nécessite une grande quantité de stockage en fonction du nombre de requêtes effectuées par l'entrée et du nombre de périphériques d'entrée connectés.
- Étant donné que le SPOOL est créé dans le stockage secondaire, le fait que de nombreux périphériques d'entrée fonctionnent simultanément peut occuper beaucoup d'espace sur le stockage secondaire et ainsi augmenter le trafic disque. Cela a pour conséquence que le disque devient de plus en plus lent à mesure que le trafic augmente de plus en plus.
- La mise en file d'attente est utilisée pour copier et exécuter des données d'un appareil plus lent vers un appareil plus rapide. Le périphérique le plus lent crée un SPOOL pour stocker les données à exploiter dans une file d'attente, et le processeur travaille dessus. Ce processus en lui-même rend le Spooling inutile dans des environnements en temps réel où nous avons besoin de résultats en temps réel du processeur. En effet, le périphérique d'entrée est plus lent et produit donc ses données à un rythme plus lent tandis que le processeur peut fonctionner plus rapidement, il passe donc au processus suivant dans la file d'attente. C'est pourquoi le résultat final est produit plus tard plutôt qu'en temps réel.
Différence entre la mise en file d'attente et la mise en mémoire tampon
La mise en file d'attente et la mise en mémoire tampon sont les deux moyens par lesquels les sous-systèmes d'E/S améliorent les performances et l'efficacité de l'ordinateur en utilisant un espace de stockage dans la mémoire principale ou sur le disque.

La différence fondamentale entre le spooling et le buffering est que le spooling chevauche les E/S d'un travail avec l'exécution d'un autre travail. En comparaison, la mise en mémoire tampon chevauche les E/S d'une tâche avec l'exécution de la même tâche. Vous trouverez ci-dessous quelques différences supplémentaires entre le spooling et le buffering, telles que :
| Termes | Mise en file d'attente | Mise en mémoire tampon |
|---|---|---|
| Définition | Le spooling, acronyme de Simultaneous Peripheral Operation Online (SPOOL), place les données dans une zone de travail temporaire pour être consultées et traitées par un autre programme ou une autre ressource. | La mise en mémoire tampon est un acte de stockage temporaire de données dans la mémoire tampon. Cela aide à faire correspondre la vitesse du flux de données entre l’expéditeur et le destinataire. |
| Besoin en ressources | La mise en file d'attente nécessite moins de gestion des ressources, car différentes ressources gèrent le processus pour des tâches spécifiques. | La mise en mémoire tampon nécessite davantage de gestion des ressources, car la même ressource gère le processus du même travail divisé. |
| Implémentation interne | La mise en file d'attente chevauche l'entrée et la sortie d'une tâche avec le calcul d'une autre tâche. | La mise en mémoire tampon chevauche l'entrée et la sortie d'une tâche avec le calcul de la même tâche. |
| Efficace | La mise en file d'attente est plus efficace que la mise en mémoire tampon. | La mise en mémoire tampon est moins efficace que la mise en file d'attente. |
| Processeur | Le spooling peut également traiter des données sur des sites distants. Le spouleur doit uniquement avertir lorsqu'un processus est terminé sur le site distant pour spouler le processus suivant sur le périphérique distant. | La mise en mémoire tampon ne prend pas en charge le traitement à distance. |
| Taille en mémoire | Il considère le disque comme une énorme bobine ou un tampon. | Le tampon est une zone limitée dans la mémoire principale. |