Pandas dataframe.corr() est utilisé pour trouver la corrélation par paire de toutes les colonnes du Pandas Dataframe en Python. N'importe lequel NaN les valeurs sont automatiquement exclues. Pour ignorer les valeurs non numériques, utilisez le paramètre numeric_only = True. Dans cet article, nous découvrirons la méthode DataFrame.corr() dans Python .
Syntaxe de la méthode Pandas DataFrame corr()
Syntaxe: DataFrame.corr(self, method='pearson', min_periods=1, numeric_only = False)
Paramètres:
- méthode :
- Pearson : coefficient de corrélation standard
- kendall : coefficient de corrélation de Kendall Tau
- Spearman : corrélation des rangs de Spearman
- min_périodes : Nombre minimum d'observations requis par paire de colonnes pour avoir un résultat valide. Actuellement disponible uniquement pour la corrélation Pearson et Spearman
- numeric_only : indique si seules les valeurs numériques doivent être utilisées ou non. Il est défini sur False par défaut.
Retour: nombre : y : DataFrame
Méthode corr() de corrélations de données Pandas
Une bonne corrélation dépend de l'utilisation, mais on peut dire sans se tromper qu'il faut au moins 0,6 (ou -0,6) pour parler d'une bonne corrélation. Un exemple simple pour montrer comment fonctionne la corrélation Python .
Python3
instruction de commutation java
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Sortir
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Création d'un exemple de trame de données
Impression des 10 premières lignes du Dataframe.
Note: La corrélation d'une variable avec elle-même est 1. Pour un lien vers le fichier CSV utilisé dans le code, cliquez sur ici
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
chaîne en caractère java
>
Sortir

Exemples de méthodes Python Pandas DataFrame corr()
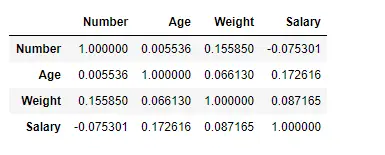
Trouver une corrélation entre les colonnes à l'aide de la méthode Pearson
Ici, nous utilisons la fonction corr() pour trouver la corrélation entre les colonnes du Dataframe à l'aide de la méthode « Pearson ». Nous n'avons que quatre colonnes numériques dans le Dataframe. Le Dataframe de sortie peut être interprété comme pour n'importe quelle cellule, la corrélation de la variable de ligne avec la variable de colonne est la valeur de la cellule. Comme mentionné précédemment, la corrélation d'une variable avec elle-même est de 1. Pour cette raison, toutes les valeurs diagonales sont de 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Sortir
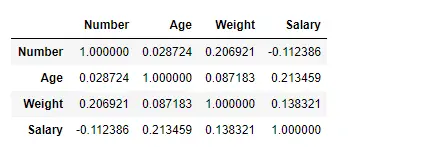
Rechercher une corrélation entre les colonnes à l'aide de la méthode Kendall
Utilisez la fonction Pandas df.corr() pour trouver la corrélation entre les colonnes du Dataframe à l'aide de la méthode « kendall ». Le Dataframe de sortie peut être interprété comme pour n'importe quelle cellule, la corrélation de la variable de ligne avec la variable de colonne est la valeur de la cellule. Comme mentionné précédemment, la corrélation d'une variable avec elle-même est de 1. Pour cette raison, toutes les valeurs diagonales sont de 1,00.
Python3
Hiba Boukhari
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
Sortir