La régression linéaire et la régression logistique sont les deux célèbres algorithmes d'apprentissage automatique qui relèvent de la technique d'apprentissage supervisé. Étant donné que les deux algorithmes sont de nature supervisée, ces algorithmes utilisent un ensemble de données étiquetées pour faire les prédictions. Mais la principale différence entre eux réside dans la manière dont ils sont utilisés. La régression linéaire est utilisée pour résoudre les problèmes de régression tandis que la régression logistique est utilisée pour résoudre les problèmes de classification. La description des deux algorithmes est donnée ci-dessous avec un tableau de différences.
Régression linéaire:
- La régression linéaire est l'un des algorithmes d'apprentissage automatique les plus simples relevant de la technique d'apprentissage supervisé et utilisé pour résoudre des problèmes de régression.
- Il est utilisé pour prédire la variable dépendante continue à l’aide de variables indépendantes.
- L'objectif de la régression linéaire est de trouver la ligne la mieux ajustée capable de prédire avec précision le résultat de la variable dépendante continue.
- Si une seule variable indépendante est utilisée pour la prédiction, elle est appelée régression linéaire simple et s'il y a plus de deux variables indépendantes, une telle régression est appelée régression linéaire multiple.
- En trouvant la droite la mieux ajustée, l'algorithme établit la relation entre la variable dépendante et la variable indépendante. Et la relation devrait être de nature linéaire.
- Le résultat de la régression linéaire ne doit être constitué que de valeurs continues telles que le prix, l'âge, le salaire, etc. La relation entre la variable dépendante et la variable indépendante peut être affichée dans l'image ci-dessous :

Dans l'image ci-dessus, la variable dépendante est sur l'axe Y (salaire) et la variable indépendante est sur l'axe X (expérience). La droite de régression peut s’écrire :
y= a<sub>0</sub>+a<sub>1</sub>x+ ε
Où un0et un1sont les coefficients et ε est le terme d'erreur.
Régression logistique:
- La régression logistique est l'un des algorithmes d'apprentissage automatique les plus populaires relevant des techniques d'apprentissage supervisé.
- Il peut être utilisé aussi bien pour les problèmes de classification que pour les problèmes de régression, mais principalement pour les problèmes de classification.
- La régression logistique est utilisée pour prédire la variable dépendante catégorielle à l'aide de variables indépendantes.
- La sortie du problème de régression logistique ne peut être qu'entre 0 et 1.
- La régression logistique peut être utilisée lorsque les probabilités entre deux classes sont requises. Par exemple s'il va pleuvoir aujourd'hui ou non, 0 ou 1, vrai ou faux, etc.
- La régression logistique est basée sur le concept d'estimation du maximum de vraisemblance. Selon cette estimation, les données observées devraient être les plus probables.
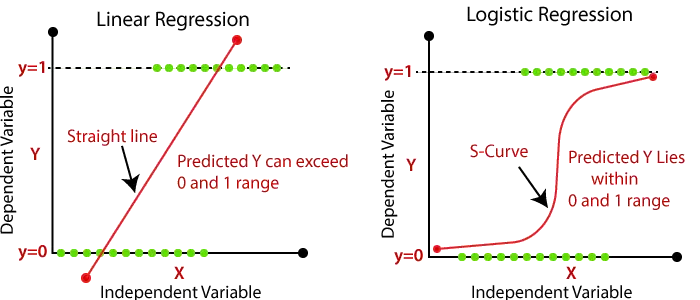
- Dans la régression logistique, nous transmettons la somme pondérée des entrées via une fonction d'activation qui peut mapper des valeurs comprises entre 0 et 1. Une telle fonction d'activation est connue sous le nom de fonction sigmoïde et la courbe obtenue est appelée courbe sigmoïde ou courbe en S. Considérez l'image ci-dessous :

- L'équation de la régression logistique est la suivante :

Différence entre la régression linéaire et la régression logistique :
| Régression linéaire | Régression logistique |
|---|---|
| La régression linéaire est utilisée pour prédire la variable dépendante continue à l'aide d'un ensemble donné de variables indépendantes. | La régression logistique est utilisée pour prédire la variable dépendante catégorielle à l'aide d'un ensemble donné de variables indépendantes. |
| La régression linéaire est utilisée pour résoudre le problème de régression. | La régression logistique est utilisée pour résoudre les problèmes de classification. |
| En régression linéaire, nous prédisons la valeur des variables continues. | Dans la régression logistique, nous prédisons les valeurs des variables catégorielles. |
| En régression linéaire, nous trouvons la droite la mieux ajustée, grâce à laquelle nous pouvons facilement prédire le résultat. | Dans la régression logistique, nous trouvons la courbe en S par laquelle nous pouvons classer les échantillons. |
| La méthode d’estimation des moindres carrés est utilisée pour estimer la précision. | La méthode d’estimation du maximum de vraisemblance est utilisée pour estimer la précision. |
| Le résultat de la régression linéaire doit être une valeur continue, telle que le prix, l'âge, etc. | Le résultat de la régression logistique doit être une valeur catégorielle telle que 0 ou 1, Oui ou Non, etc. |
| Dans la régression linéaire, il est nécessaire que la relation entre la variable dépendante et la variable indépendante soit linéaire. | Dans la régression logistique, il n'est pas nécessaire d'avoir une relation linéaire entre la variable dépendante et indépendante. |
| En régression linéaire, il peut y avoir une colinéarité entre les variables indépendantes. | Dans la régression logistique, il ne devrait pas y avoir de colinéarité entre les variables indépendantes. |