Dans la section précédente, nous avons fait une brève introduction à Apache Kafka, au système de messagerie ainsi qu'au processus de streaming. Ici, nous discuterons des concepts de base et du rôle de Kafka.
Les sujets
Généralement, un sujet fait référence à un titre particulier ou à un nom donné à des idées spécifiques interdépendantes. Dans Kafka, le mot sujet fait référence à une catégorie ou à un nom commun utilisé pour stocker et publier un flux de données particulier. Fondamentalement, les sujets dans Kafka sont similaires aux tables de la base de données, mais ne contiennent pas toutes les contraintes. Dans Kafka, nous pouvons créer n nombre de sujets comme nous le souhaitons. Il est identifié par son nom qui dépend du choix de l'utilisateur. Un producteur publie des données sur les sujets et un consommateur lit ces données à partir du sujet en s'y abonnant.
Partitions
Un sujet est divisé en plusieurs parties appelées partitions du sujet. Ces partitions sont séparées dans un ordre. Le contenu des données est stocké dans les partitions du sujet. Par conséquent, lors de la création d'un sujet, nous devons spécifier le nombre de partitions (le nombre est arbitraire et peut être modifié ultérieurement). Chaque message est stocké dans des partitions avec un identifiant incrémentiel appelé valeur de décalage. L'ordre du valeur de décalage est garanti au sein de la partition uniquement et non à travers la partition. Les décalages pour une partition sont infinis.
Note:Les données une fois écrites sur une partition ne peuvent jamais être modifiées. C'est immuable. La valeur de décalage reste toujours dans un état incrémental, elle ne retourne jamais dans un espace vide. De plus, les données sont conservées dans une partition pendant une durée limitée uniquement.
Voyons un exemple pour comprendre un sujet avec ses partitions.
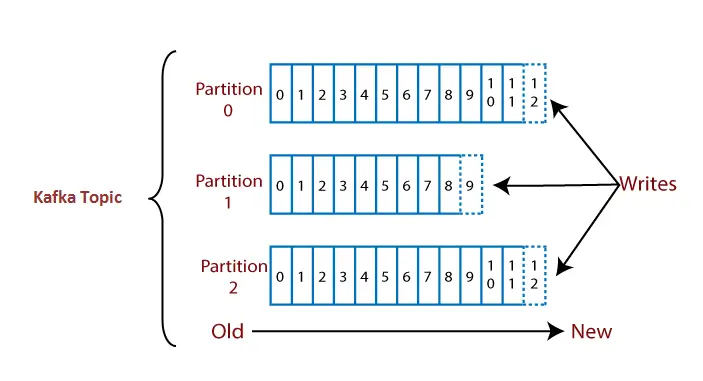
Supposons qu'il s'agisse d'un sujet contenant trois partitions 0, 1 et 2. Chaque partition a des numéros de décalage différents. Les données sont réparties entre chaque décalage de chaque partition où les données du décalage 1 de la partition 0 n'ont aucune relation avec les données du décalage 1 de la partition 1. Mais les données du décalage 1 de la partition 0 sont liées aux données contenues dans le décalage 2 de la partition 0.
Courtiers
Ici, vient le rôle d’Apache Kafka.
Un cluster Kafka est composé d'un ou plusieurs serveurs appelés courtiers ou courtiers Kafka. Un courtier est un conteneur contenant plusieurs sujets avec leurs multiples partitions. Les courtiers du cluster sont identifiés uniquement par un identifiant entier. Les courtiers Kafka sont également connus sous le nom de Courtiers bootstrap car la connexion avec l'un des courtiers signifie une connexion avec l'ensemble du cluster. Bien qu'un courtier ne contienne pas des données entières, chaque courtier du cluster connaît tous les autres courtiers, partitions ainsi que sujets.

Voici à quoi ressemble un courtier dans la figure contenant un sujet avec n nombre de partitions.
Exemple : courtiers et sujets
Supposons qu'il s'agisse d'un cluster Kafka composé de trois courtiers, à savoir Broker 1, Broker 2 et Broker 3.

Chaque courtier détient un sujet, à savoir Topic-x avec trois partitions 0,1 et 2. N'oubliez pas que toutes les partitions n'appartiennent pas à un seul courtier, elles sont toujours réparties entre chaque courtier (cela dépend de la quantité). Broker 1 et Broker 2 contiennent un autre sujet-y ayant deux partitions 0 et 1. Ainsi, Broker 3 ne contient aucune donnée du sujet-y. Il est également conclu qu'il n'existe jamais de relation entre le numéro de courtier et le numéro de partition.