Pandas
Pandas est une bibliothèque intégrée à Python qui est utilisée pour travailler avec des données relationnelles dans le langage de programmation Python. Il possède de nombreuses fonctions et structures de données qui facilitent les opérations sur les données relationnelles.
Si les données sont stockées sous forme de lignes et de colonnes ou si les données bidimensionnelles sont généralement appelées dataframes dans les pandas.
Si nous avons deux trames de données, alors avec l'aide de pandas, nous pouvons les combiner ou les fusionner en une seule trame de données. Les pandas fournissent la logique définie pour combiner les données de deux trames de données différentes ainsi que la logique pour les comparer.
1. Utilisation de la fonction concat()
En python, nous pouvons concaténer les deux dataframes à l'aide de la fonction concat() de Pandas. Nous pouvons concaténer les données par ligne ou par colonne. Cette fonction fusionne les données sur un axe (ligne ou colonne) et exécute la logique définie sur un autre axe (un autre index).
Exemple:
import pandas as pd from IPython.display import display # First DataFrame dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'Name': ['ABC', 'PQR', 'DEF', 'GHI'], 'Marks':[65,69,96,89]}) # Second DataFrame dataFrame2 = pd.DataFrame({'id': ['B1', 'B2', 'B3', 'B4'], 'Name': ['XYZ', 'TUV', 'MNO', 'JKL'], 'Marks':[56,96,69,98]}) frames = [dataFrame1, dataFrame2] result = pd.concat(frames) display(result) Sortir:
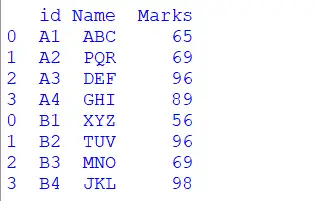
Explication:
Dans le code ci-dessus, nous avons d'abord importé la bibliothèque Pandas dans le fichier. Ensuite, nous avons créé les deux dataframes où chaque dataframe contient trois colonnes et quatre lignes. Ensuite, nous avons utilisé la fonction concat, qui concatène ces deux trames de données par ligne, et avec la fonction d'affichage, nous l'avons imprimé à l'écran.
2. Utiliser les jointures dans les pandas
Nous avons compris le concept de jointure dans la base de données où nous joignons les deux tables en fonction d'un attribut commun. La même méthode est applicable à la concaténation de dataframes. Dans la méthode simple concat(), nous avons fusionné toutes les lignes les unes sur les autres et créé la nouvelle trame de données. Dans la jointure, nous définissons quel type de jointure nous souhaitons effectuer sur la table, qu'il s'agisse d'une jointure interne ou d'une jointure externe. Quel que soit le type de jointure, qu’il s’agisse d’une jointure interne (intersection) ou d’une jointure externe (union), il sera défini dans l’attribut join.
Exemple:
tailles de police en latex
import pandas as pd from IPython.display import display dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'Name': ['ABC', 'PQR', 'TUV', 'JKL']}) dataFrame2 = pd.DataFrame({'City': ['NOIDA', 'JAIPUR', 'MANALI', 'DELHI'], 'Age': ['11', '10', '12', '17']}) # the default behaviour is join='outer' # inner join result = pd.concat([dataFrame1, dataFrame2], axis=1, join='inner') display(result) Sortir:

Explication:
Dans le code ci-dessus, nous avons deux daraframes qui contiennent toutes deux deux colonnes et quatre lignes. Les deux dataframes ont des noms de colonnes différents, et dans la fonction concat(), nous avons utilisé la jointure interne, qui prend la partie intersection.
Dans l'attribut axis, nous avons initialisé la valeur un, nous avons donc obtenu toutes les données.
Exemple:
import pandas as pd from IPython.display import display dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'Name': ['ABC', 'PQR', 'TUV', 'JKL']}) dataFrame2 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'],'City': ['NOIDA', 'JAIPUR', 'MANALI', 'DELHI'], 'Age': ['11', '10', '12', '17']}) # the default behaviour is join='outer' # inner join result = pd.concat([dataFrame1, dataFrame2], axis=0, join='inner') display(result) Sortir:
Java statique

Puisqu'il n'y a pas d'attribut commun et que la jointure interne a été appliquée, nous avons alors obtenu une trame de données vide en sortie. S'il existe un attribut commun dans les deux dataframes :
Exemple:
import pandas as pd from IPython.display import display dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'Name': ['ABC', 'PQR', 'TUV', 'JKL']}) dataFrame2 = pd.DataFrame({'id': ['B1', 'B2', 'B3', 'B4'], 'City': ['NOIDA', 'JAIPUR', 'MANALI', 'DELHI'], 'Age': ['11', '10', '12', '17']}) # the default behaviour is join='outer' # inner join result = pd.concat([dataFrame1, dataFrame2], axis=0, join='inner') display(result) Sortir:

Explication:
Dans le code ci-dessus, nous avons un attribut, « id », qui est commun, donc la trame de données est créée sur la base uniquement d'attributs communs.
3. Utilisation de la méthode append()
Au lieu de la méthode concat(), nous pouvons utiliser la méthode append(). Cette méthode append() est appliquée à l’une des trames de données.
Exemple:
import pandas as pd from IPython.display import display # First DataFrame dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'City': ['JAIPUR', 'MANALI', 'NOIDA', 'LUCKNOW']}) # Second DataFrame dataFrame2 = pd.DataFrame({'id': ['B1', 'B2', 'B3', 'B4'], 'City': ['MUMBAI', 'UDAIPUR', 'RISHIKESH', 'KASHMIR']}) # append method result = dataFrame1.append(dataFrame2) display(result) Sortir:

Explication:
Dans le code ci-dessus, nous avons fusionné deux trames de données à l'aide de la méthode append.