Dans cet article, nous discuterons de l'algorithme BFS dans la structure de données. La recherche en largeur d'abord est un algorithme de parcours de graphe qui commence à parcourir le graphe à partir du nœud racine et explore tous les nœuds voisins. Ensuite, il sélectionne le nœud le plus proche et explore tous les nœuds inexplorés. Lors de l'utilisation de BFS pour le parcours, n'importe quel nœud du graphique peut être considéré comme le nœud racine.
Il existe de nombreuses façons de parcourir le graphique, mais parmi elles, BFS est l'approche la plus couramment utilisée. Il s'agit d'un algorithme récursif pour rechercher tous les sommets d'une structure de données arborescente ou graphique. BFS classe chaque sommet du graphique en deux catégories : visité et non visité. Il sélectionne un seul nœud dans un graphique et, ensuite, visite tous les nœuds adjacents au nœud sélectionné.
Applications de l'algorithme BFS
Les applications de l'algorithme de largeur d'abord sont données comme suit -
- BFS peut être utilisé pour trouver les emplacements voisins à partir d’un emplacement source donné.
- Dans un réseau peer-to-peer, l'algorithme BFS peut être utilisé comme méthode de parcours pour trouver tous les nœuds voisins. La plupart des clients torrent, tels que BitTorrent, uTorrent, etc. utilisent ce processus pour trouver des « graines » et des « pairs » sur le réseau.
- BFS peut être utilisé dans les robots d'exploration Web pour créer des index de pages Web. C'est l'un des principaux algorithmes pouvant être utilisés pour indexer des pages Web. Il commence à parcourir à partir de la page source et suit les liens associés à la page. Ici, chaque page Web est considérée comme un nœud dans le graphique.
- BFS est utilisé pour déterminer le chemin le plus court et l'arbre couvrant minimum.
- BFS est également utilisé dans la technique de Cheney pour dupliquer le garbage collection.
- Il peut être utilisé dans la méthode Ford-Fulkerson pour calculer le débit maximum dans un réseau de flux.
Algorithme
Les étapes impliquées dans l'algorithme BFS pour explorer un graphique sont indiquées comme suit :
Étape 1: SET STATUS = 1 (état prêt) pour chaque nœud de G
constructeur en java
Étape 2: Mettez en file d'attente le nœud de départ A et définissez son STATUS = 2 (état d'attente)
Étape 3: Répétez les étapes 4 et 5 jusqu'à ce que la file d'attente soit vide.
Étape 4: Retirez un nœud N de la file d'attente. Traitez-le et définissez son STATUS = 3 (état traité).
Étape 5 : Mettez en file d'attente tous les voisins de N qui sont à l'état prêt (dont STATUS = 1) et définissez
leur STATUT = 2
fourmi contre maven
(état d'attente)
[FIN DE BOUCLE]
Étape 6 : SORTIE
Exemple d'algorithme BFS
Comprenons maintenant le fonctionnement de l'algorithme BFS en utilisant un exemple. Dans l’exemple donné ci-dessous, il existe un graphe orienté comportant 7 sommets.
programme java
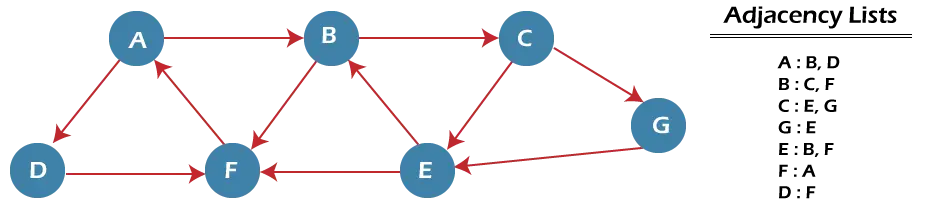
Dans le graphique ci-dessus, le chemin minimum « P » peut être trouvé en utilisant le BFS qui commencera au nœud A et se terminera au nœud E. L'algorithme utilise deux files d'attente, à savoir QUEUE1 et QUEUE2. QUEUE1 contient tous les nœuds qui doivent être traités, tandis que QUEUE2 contient tous les nœuds qui sont traités et supprimés de QUEUE1.
Commençons maintenant à examiner le graphique à partir du nœud A.
Étape 1 - Tout d'abord, ajoutez A à la file d'attente1 et NULL à la file d'attente2.
QUEUE1 = {A} QUEUE2 = {NULL} Étape 2 - Maintenant, supprimez le nœud A de la file d'attente1 et ajoutez-le dans la file d'attente2. Insérez tous les voisins du nœud A dans la file d'attente1.
QUEUE1 = {B, D} QUEUE2 = {A} Étape 3 - Maintenant, supprimez le nœud B de la file d'attente1 et ajoutez-le dans la file d'attente2. Insérez tous les voisins du nœud B dans la file d'attente1.
arraylist.sort
QUEUE1 = {D, C, F} QUEUE2 = {A, B} Étape 4 - Maintenant, supprimez le nœud D de la file d'attente1 et ajoutez-le dans la file d'attente2. Insérez tous les voisins du nœud D dans la file d'attente1. Le seul voisin du nœud D est F puisqu'il est déjà inséré, il ne sera donc pas réinséré.
QUEUE1 = {C, F} QUEUE2 = {A, B, D} Étape 5 - Supprimez le nœud C de la file d'attente1 et ajoutez-le dans la file d'attente2. Insérez tous les voisins du nœud C dans la file d'attente1.
t bascule
QUEUE1 = {F, E, G} QUEUE2 = {A, B, D, C} Étape 5 - Supprimez le nœud F de la file d'attente1 et ajoutez-le dans la file d'attente2. Insérez tous les voisins du nœud F dans la file d'attente1. Puisque tous les voisins du nœud F sont déjà présents, nous ne les réinsérerons pas.
QUEUE1 = {E, G} QUEUE2 = {A, B, D, C, F} Étape 6 - Supprimez le nœud E de la file d'attente1. Puisque tous ses voisins ont déjà été ajoutés, nous ne les réinsérerons pas. Désormais, tous les nœuds sont visités et le nœud cible E est rencontré dans la file d'attente2.
QUEUE1 = {G} QUEUE2 = {A, B, D, C, F, E} Complexité de l'algorithme BFS
La complexité temporelle de BFS dépend de la structure de données utilisée pour représenter le graphique. La complexité temporelle de l'algorithme BFS est O(V+E) , car dans le pire des cas, l'algorithme BFS explore chaque nœud et chaque bord. Dans un graphe, le nombre de sommets est O(V), tandis que le nombre d'arêtes est O(E).
La complexité spatiale de BFS peut être exprimée comme O(V) , où V est le nombre de sommets.
Implémentation de l'algorithme BFS
Voyons maintenant l'implémentation de l'algorithme BFS en Java.
Dans ce code, nous utilisons la liste de contiguïté pour représenter notre graphique. L'implémentation de l'algorithme Breadth-First Search en Java facilite grandement la gestion de la liste de contiguïté puisque nous n'avons qu'à parcourir la liste des nœuds attachés à chaque nœud une fois que le nœud est retiré de la file d'attente de la tête (ou du début) de la file d'attente.
Dans cet exemple, le graphique que nous utilisons pour démontrer le code est donné comme suit :

import java.io.*; import java.util.*; public class BFSTraversal { private int vertex; /* total number number of vertices in the graph */ private LinkedList adj[]; /* adjacency list */ private Queue que; /* maintaining a queue */ BFSTraversal(int v) { vertex = v; adj = new LinkedList[vertex]; for (int i=0; i<v; i++) { adj[i]="new" linkedlist(); } que="new" void insertedge(int v,int w) adj[v].add(w); * adding an edge to the adjacency list (edges are bidirectional in this example) bfs(int n) boolean nodes[]="new" boolean[vertex]; initialize array for holding data int a="0;" nodes[n]="true;" que.add(n); root node is added top of queue while (que.size() !="0)" n="que.poll();" remove element system.out.print(n+' '); print (int i="0;" < adj[n].size(); iterate through linked and push all neighbors into if (!nodes[a]) only insert nodes they have not been explored already nodes[a]="true;" que.add(a); public static main(string args[]) bfstraversal graph="new" bfstraversal(10); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, graph.insertedge(6, graph.insertedge(7, 8); system.out.println('breadth first traversal is:'); graph.bfs(2); pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/64/bfs-algorithm-3.webp" alt="Breadth First Search Algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the Breadth-first search technique along with its example, complexity, and implementation in java programming language. Here, we have also seen the real-life applications of BFS that show it the important data structure algorithm.</p> <p>So, that's all about the article. Hope, it will be helpful and informative to you.</p> <hr></v;>