Les algorithmes de régression et de classification sont des algorithmes d’apprentissage supervisé. Les deux algorithmes sont utilisés pour la prédiction dans l’apprentissage automatique et fonctionnent avec les ensembles de données étiquetés. Mais la différence entre les deux réside dans la manière dont ils sont utilisés pour différents problèmes d’apprentissage automatique.
La principale différence entre les algorithmes de régression et de classification pour lesquels les algorithmes de régression sont utilisés prédire la continuité des valeurs telles que le prix, le salaire, l'âge, etc. et des algorithmes de classification sont utilisés pour prédire/Classer les valeurs discrètes tels que Homme ou Femme, Vrai ou Faux, Spam ou pas spam, etc.
Considérez le diagramme ci-dessous :
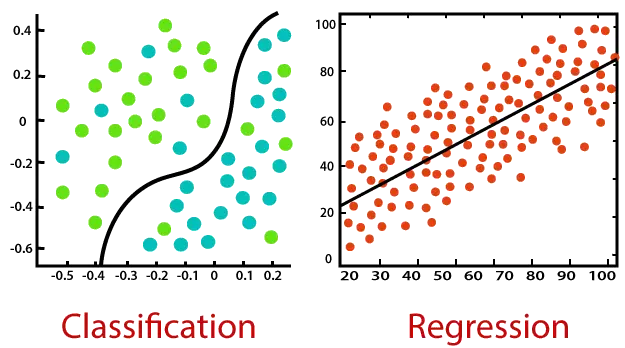
Classification:
La classification est un processus de recherche d'une fonction qui aide à diviser l'ensemble de données en classes basées sur différents paramètres. Dans Classification, un programme informatique est formé sur l'ensemble de données de formation et, sur la base de cette formation, il classe les données en différentes classes.
La tâche de l'algorithme de classification est de trouver la fonction de mappage pour mapper l'entrée (x) à la sortie discrète (y).
Exemple: Le meilleur exemple pour comprendre le problème de classification est la détection du spam par courrier électronique. Le modèle est formé sur la base de millions d'e-mails sur différents paramètres, et chaque fois qu'il reçoit un nouvel e-mail, il identifie si l'e-mail est du spam ou non. Si l'e-mail est du spam, il est déplacé vers le dossier Spam.
Types d'algorithmes de classification ML :
Les algorithmes de classification peuvent être divisés dans les types suivants :
- Régression logistique
- K-Voisins les plus proches
- Machines à vecteurs de support
- SVM du noyau
- Na�ve Bayes
- Classification de l'arbre de décision
- Classification aléatoire des forêts
Régression:
La régression est un processus permettant de trouver les corrélations entre les variables dépendantes et indépendantes. Cela aide à prédire les variables continues telles que la prédiction de Tendances du marché , prévision des prix des logements, etc.
La tâche de l'algorithme de régression est de trouver la fonction de mappage pour mapper la variable d'entrée (x) à la variable de sortie continue (y).
Exemple: Supposons que nous voulions faire des prévisions météorologiques, donc pour cela, nous utiliserons l'algorithme de régression. En prévision météorologique, le modèle est formé sur les données passées et, une fois la formation terminée, il peut facilement prédire la météo des jours à venir.
Types d’algorithmes de régression :
- Régression linéaire simple
- La régression linéaire multiple
- Régression polynomiale
- Régression du vecteur de support
- Régression de l'arbre de décision
- Régression de forêt aléatoire
Différence entre régression et classification
| Algorithme de régression | Algorithme de classification |
|---|---|
| En régression, la variable de sortie doit être de nature continue ou de valeur réelle. | Dans Classification, la variable de sortie doit être une valeur discrète. |
| La tâche de l'algorithme de régression est de mapper la valeur d'entrée (x) avec la variable de sortie continue (y). | La tâche de l'algorithme de classification est de mapper la valeur d'entrée (x) avec la variable de sortie discrète (y). |
| Les algorithmes de régression sont utilisés avec des données continues. | Les algorithmes de classification sont utilisés avec des données discrètes. |
| Dans la régression, nous essayons de trouver la ligne la mieux ajustée, qui permet de prédire le résultat avec plus de précision. | Dans Classification, nous essayons de trouver la limite de décision, qui peut diviser l'ensemble de données en différentes classes. |
| Les algorithmes de régression peuvent être utilisés pour résoudre les problèmes de régression tels que la prévision météorologique, la prévision du prix de l'immobilier, etc. | Les algorithmes de classification peuvent être utilisés pour résoudre des problèmes de classification tels que l'identification des courriers indésirables, la reconnaissance vocale, l'identification des cellules cancéreuses, etc. |
| L'algorithme de régression peut être divisé en régression linéaire et non linéaire. | Les algorithmes de classification peuvent être divisés en classificateur binaire et classificateur multi-classe. |