Python est un excellent langage pour analyser des données, principalement en raison de son fantastique écosystème de solutions centrées sur les données. Python paquets. Pandas est l'un de ces packages et facilite grandement l'importation et l'analyse des données.
Pandas DataFrame moyenne()
Pandas dataframe.mean() La fonction renvoie la moyenne des valeurs de l'axe demandé. Si la méthode est appliquée sur un objet de la série pandas, alors la méthode renvoie une valeur scalaire qui est la valeur moyenne de toutes les observations du Cadre de données Pandas . Si la méthode est appliquée sur un objet Pandas Dataframe, alors la méthode renvoie un Série Pandas objet qui contient la moyenne des valeurs sur l’axe spécifié.
Syntaxe: DataFrame.mean(axis=0, skipna=True, level=None, numeric_only=False, **kwargs)
Paramètres :
- axe : {index (0), colonnes (1)}
- commande : Exclure les valeurs NA/nulles lors du calcul du résultat
- niveau : Si l'axe est un MultiIndex (hiérarchique), comptez le long d'un niveau particulier, en vous transformant en une série.
- numérique_seulement : Inclut uniquement les colonnes float, int et booléennes. Si Aucun, tentera de tout utiliser, puis utilisera uniquement des données numériques. Non implémenté pour les séries.
Retour : moyenne : Série ou DataFrame (si niveau spécifié)
inurl :.git/head
Exemples Pandas DataFrame.mean()
Exemple 1:
Utilisez la fonction Mean() pour trouver la moyenne de toutes les observations sur l’axe d’index.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 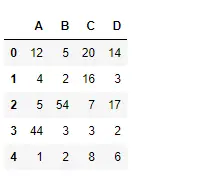
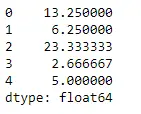
Utilisons la fonction Dataframe.mean() pour trouver la moyenne sur l'axe d'index.
Python # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Sortir:
Exemple 2 :
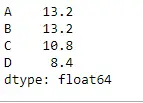
Utilisez la fonction Mean() sur une Dataframe qui n’a aucune valeur. Trouvez également la moyenne sur l’axe des colonnes.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Sortir: