- dnorme()
dnorm(x, mean, sd)>pnorm()
pnorm(x, mean, sd)>qnorme()
qnorm(p, mean, sd)>rnorme()
rnorm(n, mean, sd)>où,
– X représente l'ensemble de données de valeurs - moyenne(x) représente la moyenne de l'ensemble de données X . Sa valeur par défaut est 0.>– sd(x) représente l'écart type de l'ensemble de données X . Sa valeur par défaut est 1.>– n est le nombre d’observations. – p est un vecteur de probabilités
Fonctions pour générer une distribution normale dans R
dnorme()
dnorm()> la fonction dans la programmation R mesure la fonction de densité de la distribution. Dans les statistiques, il est mesuré par la formule ci-dessous :>où,
 est méchant et
est méchant et 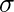 est l’écart type. Syntaxe :
est l’écart type. Syntaxe : dnorm(x, mean, sd)>Exemple:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Sortir:
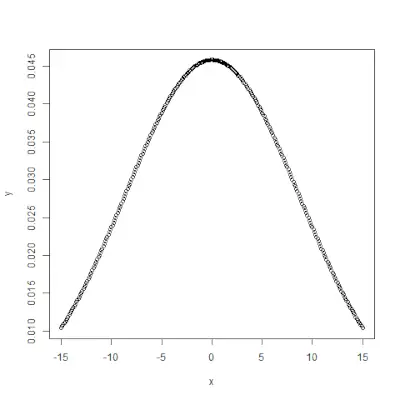
pnorm()
pnorm()> La fonction est la fonction de distribution cumulative qui mesure la probabilité qu'un nombre aléatoire X prenne une valeur inférieure ou égale à x, c'est-à-dire qu'en statistique, il est donné par->Syntaxe:
pnorm(x, mean, sd)>Exemple:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Sortir :
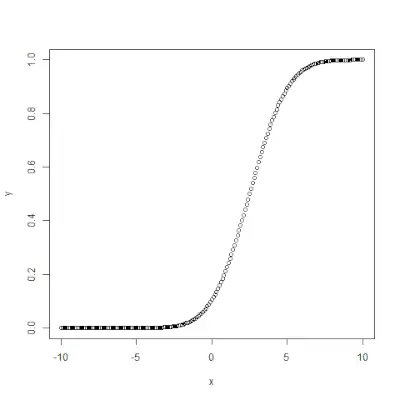
qnorme()
qnorm()> la fonction est l'inverse de pnorm()>fonction. Il prend la valeur de probabilité et donne un résultat qui correspond à la valeur de probabilité. Ceci est utile pour trouver les centiles d’une distribution normale. Syntaxe: qnorm(p, mean, sd)>Exemple:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>Sortir:
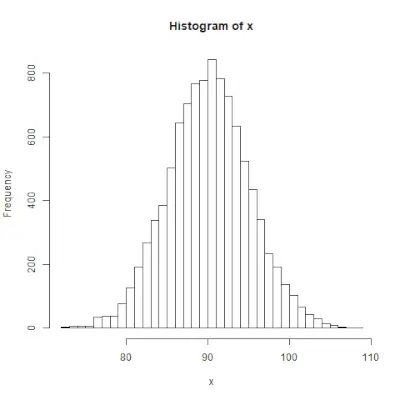
rnorme()
rnorm()> La fonction dans la programmation R est utilisée pour générer un vecteur de nombres aléatoires normalement distribués. Syntaxe: rnorm(x, mean, sd)>Exemple:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>Sortir :