Un processus peut être de deux types :
- Processus indépendant.
- Processus de coopération.
Un processus indépendant n'est pas affecté par l'exécution d'autres processus alors qu'un processus coopérant peut être affecté par d'autres processus en cours d'exécution. Bien que l’on puisse penser que ces processus, qui s’exécutent indépendamment, s’exécuteront de manière très efficace, en réalité, il existe de nombreuses situations dans lesquelles la nature coopérative peut être utilisée pour augmenter la vitesse de calcul, la commodité et la modularité. La communication inter-processus (IPC) est un mécanisme qui permet aux processus de communiquer entre eux et de synchroniser leurs actions. La communication entre ces processus peut être considérée comme une méthode de coopération entre eux. Les processus peuvent communiquer entre eux via :
- La memoire partagée
- Passage de messages
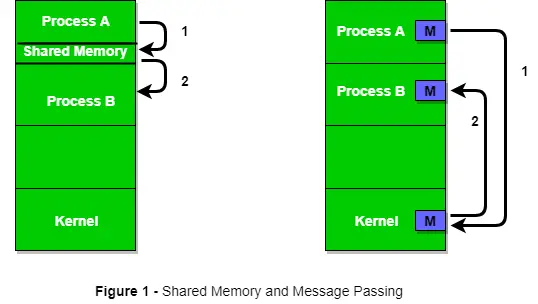
La figure 1 ci-dessous montre une structure de base de communication entre les processus via la méthode de mémoire partagée et via la méthode de transmission de messages.
Un système d'exploitation peut implémenter les deux méthodes de communication. Tout d’abord, nous discuterons des méthodes de communication en mémoire partagée, puis de transmission de messages. La communication entre les processus utilisant la mémoire partagée nécessite que les processus partagent une variable, et cela dépend entièrement de la manière dont le programmeur l'implémentera. Une façon de communiquer utilisant la mémoire partagée peut être imaginée comme ceci : supposons que processus1 et processus2 s'exécutent simultanément et qu'ils partagent certaines ressources ou utilisent des informations d'un autre processus. Process1 génère des informations sur certains calculs ou ressources utilisées et les conserve sous forme d'enregistrement dans la mémoire partagée. Lorsque le processus2 a besoin d'utiliser les informations partagées, il archivera l'enregistrement stocké dans la mémoire partagée, prendra note des informations générées par le processus1 et agira en conséquence. Les processus peuvent utiliser la mémoire partagée pour extraire des informations sous forme d'enregistrement à partir d'un autre processus ainsi que pour fournir des informations spécifiques à d'autres processus.
Discutons d'un exemple de communication entre processus utilisant la méthode de la mémoire partagée.
i) Méthode de mémoire partagée
Ex : problème producteur-consommateur
Il existe deux processus : producteur et consommateur. Le producteur produit certains articles et le consommateur consomme cet article. Les deux processus partagent un espace commun ou un emplacement mémoire appelé tampon où l'élément produit par le producteur est stocké et à partir duquel le consommateur consomme l'élément si nécessaire. Il existe deux versions de ce problème : la première est connue sous le nom de problème de tampon illimité dans lequel le producteur peut continuer à produire des éléments et il n'y a aucune limite sur la taille du tampon, la seconde est connue sous le nom de problème de tampon limité dans lequel le producteur peut produire jusqu'à un certain nombre d'articles avant de commencer à attendre que le consommateur le consomme. Nous discuterons du problème du tampon limité. Premièrement, le producteur et le consommateur partageront une mémoire commune, puis le producteur commencera à produire des articles. Si l'article total produit est égal à la taille du tampon, le producteur attendra qu'il soit consommé par le consommateur. De même, le consommateur vérifiera d'abord la disponibilité de l'article. Si aucun article n'est disponible, le Consommateur attendra que le Producteur le produise. S'il y a des articles disponibles, le consommateur les consommera. Le pseudo-code à démontrer est fourni ci-dessous :
Données partagées entre les deux processus
C
#define buff_max 25> #define mod %> >struct> item{> >// different member of the produced data> >// or consumed data> >---------> >}> > >// An array is needed for holding the items.> >// This is the shared place which will be> >// access by both process> >// item shared_buff [ buff_max ];> > >// Two variables which will keep track of> >// the indexes of the items produced by producer> >// and consumer The free index points to> >// the next free index. The full index points to> >// the first full index.> >int> free_index = 0;> >int> full_index = 0;> > |
>
>
Code de processus du producteur
C
item nextProduced;> > >while>(1){> > >// check if there is no space> >// for production.> >// if so keep waiting.> >while>((free_index+1) mod buff_max == full_index);> > >shared_buff[free_index] = nextProduced;> >free_index = (free_index + 1) mod buff_max;> >}> |
>
>
Code de processus de consommation
C
item nextConsumed;> > >while>(1){> > >// check if there is an available> >// item for consumption.> >// if not keep on waiting for> >// get them produced.> >while>((free_index == full_index);> > >nextConsumed = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >}> |
>
>
Dans le code ci-dessus, le producteur recommencera à produire lorsque le mod buff max (free_index+1) sera gratuit car s'il n'est pas gratuit, cela implique qu'il y a encore des objets qui peuvent être consommés par le consommateur donc il n'est pas nécessaire pour produire davantage. De même, si l’index gratuit et l’index complet pointent vers le même index, cela implique qu’il n’y a aucun élément à consommer.
Implémentation globale du C++ :
C++
#include> #include> #include> #include> #define buff_max 25> #define mod %> struct> item {> >// different member of the produced data> >// or consumed data> >// ---------> };> // An array is needed for holding the items.> // This is the shared place which will be> // access by both process> // item shared_buff[buff_max];> // Two variables which will keep track of> // the indexes of the items produced by producer> // and consumer The free index points to> // the next free index. The full index points to> // the first full index.> std::atomic<>int>>free_index(0);> std::atomic<>int>>index_complet(0);> std::mutex mtx;> void> producer() {> >item new_item;> >while> (>true>) {> >// Produce the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >// Add the item to the buffer> >while> (((free_index + 1) mod buff_max) == full_index) {> >// Buffer is full, wait for consumer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Add the item to the buffer> >// shared_buff[free_index] = new_item;> >free_index = (free_index + 1) mod buff_max;> >mtx.unlock();> >}> }> void> consumer() {> >item consumed_item;> >while> (>true>) {> >while> (free_index == full_index) {> >// Buffer is empty, wait for producer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Consume the item from the buffer> >// consumed_item = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >mtx.unlock();> >// Consume the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> }> int> main() {> >// Create producer and consumer threads> >std::vectorthread>fils; threads.emplace_back(producteur); threads.emplace_back(consommateur); // Attendez que les threads se terminent pour (auto& thread : threads) { thread.join(); } renvoie 0 ; }> |
>
>
if else, instructions java
Notez que la classe atomique est utilisée pour garantir que les variables partagées free_index et full_index sont mises à jour de manière atomique. Le mutex est utilisé pour protéger la section critique où l'on accède au tampon partagé. La fonction sleep_for est utilisée pour simuler la production et la consommation d'articles.
ii) Méthode de transmission de messagerie
Nous allons maintenant commencer notre discussion sur la communication entre les processus via la transmission de messages. Dans cette méthode, les processus communiquent entre eux sans utiliser aucune sorte de mémoire partagée. Si deux processus p1 et p2 veulent communiquer entre eux, ils procèdent de la manière suivante :
- Établir un lien de communication (si un lien existe déjà, inutile de le rétablir.)
- Commencez à échanger des messages en utilisant des primitives de base.
Nous avons besoin d'au moins deux primitives :
– envoyer (message, destination) ou envoyer (message)
– recevoir (message, hôte) ou recevoir (message)

La taille du message peut être de taille fixe ou de taille variable. S'il est de taille fixe, c'est facile pour un concepteur de système d'exploitation mais compliqué pour un programmeur et s'il est de taille variable alors c'est facile pour un programmeur mais compliqué pour le concepteur de système d'exploitation. Un message standard peut comporter deux parties : en-tête et corps.
Le partie d'en-tête est utilisé pour stocker le type de message, l'identifiant de destination, l'identifiant de source, la longueur du message et les informations de contrôle. Les informations de contrôle contiennent des informations telles que ce qu'il faut faire en cas de manque d'espace tampon, le numéro de séquence et la priorité. Généralement, le message est envoyé en utilisant le style FIFO.
Message passant par le lien de communication.
Lien de communication directe et indirecte
Nous allons maintenant commencer notre discussion sur les méthodes de mise en œuvre des liens de communication. Lors de la mise en œuvre du lien, certaines questions doivent être gardées à l'esprit, telles que :
- Comment s’établissent les liens ?
- Un lien peut-il être associé à plus de deux processus ?
- Combien de liens peut-il y avoir entre chaque paire de processus communicants ?
- Quelle est la capacité d'un lien ? La taille d'un message que le lien peut accueillir est-elle fixe ou variable ?
- Un lien est-il unidirectionnel ou bidirectionnel ?
Un lien a une certaine capacité qui détermine le nombre de messages qui peuvent y résider temporairement pour lesquels chaque lien est associé à une file d'attente qui peut être de capacité nulle, de capacité limitée ou de capacité illimitée. En capacité nulle, l'expéditeur attend que le destinataire l'informe qu'il a reçu le message. Dans les cas de capacité non nulle, un processus ne sait pas si un message a été reçu ou non après l'opération d'envoi. Pour cela, l’expéditeur doit communiquer explicitement avec le destinataire. La mise en œuvre du lien dépend de la situation, il peut s'agir soit d'un lien de communication direct, soit d'un lien de communication indirect.
Liens de communication directe sont mis en œuvre lorsque les processus utilisent un identifiant de processus spécifique pour la communication, mais il est difficile d'identifier l'expéditeur à l'avance.
Par exemple le serveur d'impression.
Communication indirecte se fait via une boîte aux lettres partagée (port), qui consiste en une file d'attente de messages. L'expéditeur conserve le message dans la boîte aux lettres et le destinataire le récupère.
Message passant par l'échange des messages.
Transmission de messages synchrone et asynchrone :
Un processus bloqué est un processus qui attend un événement, tel qu'une ressource devenant disponible ou la fin d'une opération d'E/S. L'IPC est possible entre les processus sur le même ordinateur ainsi que sur les processus exécutés sur des ordinateurs différents, c'est-à-dire dans un système en réseau/distribué. Dans les deux cas, le processus peut ou non être bloqué lors de l'envoi d'un message ou de la tentative de réception d'un message, de sorte que la transmission du message peut être bloquante ou non bloquante. Le blocage est considéré synchrone et blocage de l'envoi signifie que l'expéditeur sera bloqué jusqu'à ce que le message soit reçu par le destinataire. De la même manière, blocage de la réception le récepteur est bloqué jusqu'à ce qu'un message soit disponible. Le non-blocage est considéré asynchrone et l'envoi non bloquant permet à l'expéditeur d'envoyer le message et de continuer. De même, la réception non bloquante permet au destinataire de recevoir un message valide ou nul. Après une analyse minutieuse, nous pouvons arriver à la conclusion que pour un expéditeur, il est plus naturel de ne pas bloquer après la transmission du message, car il peut être nécessaire d'envoyer le message à différents processus. Cependant, l'expéditeur attend un accusé de réception de la part du destinataire en cas d'échec de l'envoi. De même, il est plus naturel qu'un récepteur bloque après avoir émis la réception, car les informations du message reçu peuvent être utilisées pour une exécution ultérieure. Dans le même temps, si l’envoi du message échoue toujours, le destinataire devra attendre indéfiniment. C'est pourquoi nous considérons également l'autre possibilité de transmission de messages. Il existe essentiellement trois combinaisons préférées :
- Blocage de l'envoi et blocage de la réception
- Envoi non bloquant et réception non bloquante
- Envoi non bloquant et réception bloquante (principalement utilisé)
Dans le passage de messages directs , Le processus qui souhaite communiquer doit nommer explicitement le destinataire ou l'expéditeur de la communication.
par exemple. envoyer (p1, message) signifie envoyer le message à p1.
De la même manière, recevoir (p2, message) signifie recevoir le message de p2.
Dans cette méthode de communication, la liaison de communication est établie automatiquement, qui peut être unidirectionnelle ou bidirectionnelle, mais une liaison peut être utilisée entre une paire d'expéditeur et de destinataire et une paire d'expéditeur et de destinataire ne doit pas posséder plus d'une paire de liens. La symétrie et l'asymétrie entre l'envoi et la réception peuvent également être implémentées, c'est-à-dire soit les deux processus se nommeront mutuellement pour l'envoi et la réception des messages, soit seul l'expéditeur nommera le destinataire pour envoyer le message et il n'est pas nécessaire que le destinataire nomme l'expéditeur pour recevoir le message. Le problème avec cette méthode de communication est que si le nom d’un processus change, cette méthode ne fonctionnera pas.
Dans Passage de messages indirects , les processus utilisent des boîtes aux lettres (également appelées ports) pour envoyer et recevoir des messages. Chaque boîte aux lettres possède un identifiant unique et les processus ne peuvent communiquer que s'ils partagent une boîte aux lettres. Lien établi uniquement si les processus partagent une boîte aux lettres commune et qu'un seul lien peut être associé à plusieurs processus. Chaque paire de processus peut partager plusieurs liens de communication et ces liens peuvent être unidirectionnels ou bidirectionnels. Supposons que deux processus souhaitent communiquer via le passage de messages indirects, les opérations requises sont : créer une boîte aux lettres, utiliser cette boîte aux lettres pour envoyer et recevoir des messages, puis détruire la boîte aux lettres. Les primitives standards utilisées sont : envoyer un message) ce qui signifie envoyer le message à la boîte aux lettres A. La primitive pour recevoir le message fonctionne également de la même manière, par ex. reçu (A, message) . Il y a un problème avec cette implémentation de boîte aux lettres. Supposons qu'il y ait plus de deux processus partageant la même boîte aux lettres et supposons que le processus p1 envoie un message à la boîte aux lettres, quel processus sera le destinataire ? Ce problème peut être résolu soit en imposant que seuls deux processus puissent partager une seule boîte aux lettres, soit en imposant qu'un seul processus soit autorisé à exécuter la réception à un moment donné, soit en sélectionnant n'importe quel processus au hasard et en informant l'expéditeur du destinataire. Une boîte aux lettres peut être rendue privée pour une seule paire expéditeur/destinataire et peut également être partagée entre plusieurs paires expéditeur/destinataire. Le port est une implémentation d'une telle boîte aux lettres qui peut avoir plusieurs expéditeurs et un seul destinataire. Il est utilisé dans les applications client/serveur (dans ce cas le serveur est le récepteur). Le port appartient au processus récepteur et est créé par le système d'exploitation à la demande du processus récepteur. Il peut être détruit à la demande du même processeur récepteur lorsque le récepteur se termine. Il est possible d'imposer qu'un seul processus soit autorisé à exécuter la réception en utilisant le concept d'exclusion mutuelle. Boîte aux lettres mutex est créé et partagé par n processus. L'expéditeur n'est pas bloquant et envoie le message. Le premier processus qui exécute la réception entrera dans la section critique et tous les autres processus seront bloqués et attendront.
Discutons maintenant du problème Producteur-Consommateur en utilisant le concept de transmission de messages. Le producteur place des éléments (à l'intérieur des messages) dans la boîte aux lettres et le consommateur peut consommer un élément lorsqu'au moins un message est présent dans la boîte aux lettres. Le code est donné ci-dessous :
Code du producteur
C
void> Producer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Consumer, &m);> >item = produce();> >build_message(&m , item ) ;> >send(Consumer, &m);> >}> >}> |
>
>
Code de la consommation
C
void> Consumer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Producer, &m);> >item = extracted_item();> >send(Producer, &m);> >consume_item(item);> >}> >}> |
>
>
Exemples de systèmes IPC
- Posix : utilise la méthode de la mémoire partagée.
- Mach : utilise le passage de messages
- Windows XP : utilise la transmission de messages à l'aide d'appels procéduraux locaux
Communication en architecture client/serveur :
Il existe différents mécanismes :
- Tuyau
- Prise
- Appels procéduraux à distance (RPC)
Les trois méthodes ci-dessus seront discutées dans des articles ultérieurs car elles sont toutes assez conceptuelles et méritent leurs propres articles séparés.
Les références:
- Concepts du système d'exploitation par Galvin et al.
- Notes de cours/ppt d'Ariel J. Frank, Université Bar-Ilan
La communication inter-processus (IPC) est le mécanisme par lequel les processus ou les threads peuvent communiquer et échanger des données entre eux sur un ordinateur ou sur un réseau. L'IPC est un aspect important des systèmes d'exploitation modernes, car il permet à différents processus de fonctionner ensemble et de partager des ressources, ce qui conduit à une efficacité et une flexibilité accrues.
Avantages du CIP :
- Permet aux processus de communiquer entre eux et de partager des ressources, ce qui conduit à une efficacité et une flexibilité accrues.
- Facilite la coordination entre plusieurs processus, conduisant à de meilleures performances globales du système.
- Permet la création de systèmes distribués pouvant s'étendre sur plusieurs ordinateurs ou réseaux.
- Peut être utilisé pour implémenter divers protocoles de synchronisation et de communication, tels que des sémaphores, des canaux et des sockets.
Inconvénients de l'IPC :
- Augmente la complexité du système, ce qui rend plus difficile la conception, la mise en œuvre et le débogage.
- Peut introduire des failles de sécurité, car les processus peuvent être en mesure d'accéder ou de modifier des données appartenant à d'autres processus.
- Nécessite une gestion minutieuse des ressources système, telles que la mémoire et le temps CPU, pour garantir que les opérations IPC ne dégradent pas les performances globales du système.
Peut entraîner des incohérences dans les données si plusieurs processus tentent d'accéder ou de modifier les mêmes données en même temps. - Dans l'ensemble, les avantages de l'IPC l'emportent sur les inconvénients, car il s'agit d'un mécanisme nécessaire pour les systèmes d'exploitation modernes et permet aux processus de fonctionner ensemble et de partager des ressources de manière flexible et efficace. Cependant, il faut veiller à concevoir et à mettre en œuvre soigneusement les systèmes IPC, afin d'éviter d'éventuelles vulnérabilités de sécurité et problèmes de performances.
Plus de référence :
http://nptel.ac.in/courses/106108101/pdf/Lecture_Notes/Mod%207_LN.pdf
https://www.youtube.com/watch?v=lcRqHwIn5Dk