L'architecture suivante explique le flux de soumission des requêtes dans Hive.
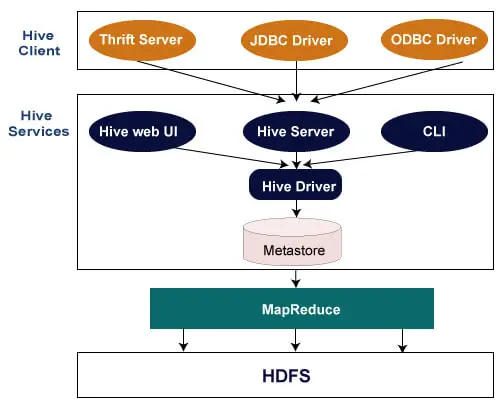
Client Hive
Hive permet d'écrire des applications dans différents langages, notamment Java, Python et C++. Il prend en charge différents types de clients tels que : -
- Thrift Server - Il s'agit d'une plate-forme de fournisseur de services multilingue qui répond aux requêtes de tous les langages de programmation prenant en charge Thrift.
- Pilote JDBC - Il est utilisé pour établir une connexion entre les applications Hive et Java. Le Driver JDBC est présent dans la classe org.apache.hadoop.hive.jdbc.HiveDriver.
- Pilote ODBC - Il permet aux applications prenant en charge le protocole ODBC de se connecter à Hive.
Services de la ruche
Voici les services fournis par Hive : -
- Hive CLI - La Hive CLI (Command Line Interface) est un shell où nous pouvons exécuter des requêtes et des commandes Hive.
- Interface utilisateur Web Hive - L'interface utilisateur Web Hive n'est qu'une alternative à Hive CLI. Il fournit une interface graphique Web pour exécuter des requêtes et des commandes Hive.
- Hive MetaStore - Il s'agit d'un référentiel central qui stocke toutes les informations de structure des différentes tables et partitions de l'entrepôt. Il comprend également les métadonnées de la colonne et ses informations de type, les sérialiseurs et désérialiseurs utilisés pour lire et écrire des données et les fichiers HDFS correspondants dans lesquels les données sont stockées.
- Serveur Hive - Il est appelé Apache Thrift Server. Il accepte la demande de différents clients et la fournit à Hive Driver.
- Pilote Hive - Il reçoit des requêtes de différentes sources telles que l'interface utilisateur Web, la CLI, Thrift et le pilote JDBC/ODBC. Il transfère les requêtes au compilateur.
- Compilateur Hive - Le but du compilateur est d'analyser la requête et d'effectuer une analyse sémantique sur les différents blocs et expressions de requête. Il convertit les instructions HiveQL en tâches MapReduce.
- Hive Execution Engine - Optimizer génère le plan logique sous la forme de DAG de tâches de réduction de mappage et de tâches HDFS. Au final, le moteur d'exécution exécute les tâches entrantes dans l'ordre de leurs dépendances.