Qu’est-ce que le cache LRU ?
Les algorithmes de remplacement du cache sont conçus efficacement pour remplacer le cache lorsque l'espace est plein. Le Le moins récemment utilisé (LRU) est l'un de ces algorithmes. Comme son nom l'indique, lorsque la mémoire cache est pleine, LRU sélectionne les données les moins récemment utilisées et les supprime afin de libérer de l'espace pour les nouvelles données. La priorité des données dans le cache change en fonction des besoins de ces données, c'est-à-dire que si certaines données sont récupérées ou mises à jour récemment, la priorité de ces données sera modifiée et attribuée à la priorité la plus élevée, et la priorité des données diminuera si elles le sont. reste inutilisé opérations après opérations.
Table des matières
- Qu’est-ce que le cache LRU ?
- Opérations sur le cache LRU :
- Fonctionnement du cache LRU :
- Façons d’implémenter le cache LRU :
- Implémentation du cache LRU à l'aide de la file d'attente et du hachage :
- Implémentation du cache LRU à l'aide de la liste doublement liée et du hachage :
- Implémentation du cache LRU à l'aide de Deque & Hashmap :
- Implémentation du cache LRU à l'aide de Stack & Hashmap :
- Cache LRU à l'aide de l'implémentation de compteur :
- Implémentation du cache LRU à l'aide des mises à jour différées :
- Analyse de la complexité du cache LRU :
- Avantages du cache LRU :
- Inconvénients du cache LRU :
- Application réelle du cache LRU :
LRU l'algorithme est un problème standard et il peut avoir des variations selon les besoins, par exemple dans les systèmes d'exploitation LRU joue un rôle crucial car il peut être utilisé comme algorithme de remplacement de page afin de minimiser les défauts de page.
Opérations sur le cache LRU :
- LRUCache (Capacité c) : Initialiser le cache LRU avec une capacité de taille positive c.
- Obtenir la clé) : Renvoie la valeur de la clé ' k' s'il est présent dans le cache sinon il renvoie -1. Met également à jour la priorité des données dans le cache LRU.
- put (clé, valeur): Mettez à jour la valeur de la clé si cette clé existe. Sinon, ajoutez une paire clé-valeur au cache. Si le nombre de clés dépasse la capacité du cache LRU, ignorez la clé la moins récemment utilisée.
Fonctionnement du cache LRU :
Supposons que nous ayons un cache LRU de capacité 3 et que nous souhaitions effectuer les opérations suivantes :
- Mettez (key=1, value=A) dans le cache
- Mettez (key=2, value=B) dans le cache
- Mettez (key=3, value=C) dans le cache
- Récupérer (clé = 2) du cache
- Récupérer (clé = 4) du cache
- Mettez (key=4, value=D) dans le cache
- Mettez (key=3, value=E) dans le cache
- Récupérer (clé = 4) du cache
- Mettez (key=1, value=A) dans le cache
Les opérations ci-dessus sont effectuées les unes après les autres comme indiqué dans l'image ci-dessous :
Explication détaillée de chaque opération :
- Put (touche 1, valeur A) : Puisque le cache LRU a une capacité vide = 3, aucun remplacement n'est nécessaire et nous mettons {1 : A} en haut, c'est-à-dire que {1 : A} a la priorité la plus élevée.
- Put (touche 2, valeur B) : Puisque le cache LRU a une capacité vide = 2, encore une fois, aucun remplacement n'est nécessaire, mais maintenant le {2 : B} a la priorité la plus élevée et la priorité de {1 : A} diminue.
- Put (touche 3, valeur C) : Il y a toujours 1 espace vide vacant dans le cache, donc mettez {3 : C} sans aucun remplacement, remarquez maintenant que le cache est plein et l'ordre de priorité actuel du plus haut au plus bas est {3:C}, {2:B }, {1 : A}.
- Obtenir (clé 2) : Désormais, la valeur de retour de key=2 pendant cette opération, également puisque key=2 est utilisé, le nouvel ordre de priorité est désormais {2:B}, {3:C}, {1:A}
- Obtenez (clé 4) : Observez que la clé 4 n'est pas présente dans le cache, nous renvoyons '-1' pour cette opération.
- Put (touche 4, valeur D) : Observez que le cache est COMPLET, utilisez maintenant l'algorithme LRU pour déterminer quelle clé a été la moins récemment utilisée. Puisque {1:A} avait la moindre priorité, supprimez {1:A} de notre cache et mettez {4:D} dans le cache. Notez que le nouvel ordre de priorité est {4:D}, {2:B}, {3:C}
- Put (touche 3, valeur E) : Puisque key=3 était déjà présent dans le cache avec une valeur=C, cette opération n'entraînera donc la suppression d'aucune clé, mais mettra plutôt à jour la valeur de key=3 en ' ET' . Désormais, le nouvel ordre de priorité deviendra {3:E}, {4:D}, {2:B}
- Obtenir (clé 4) : Renvoie la valeur de key=4. Désormais, la nouvelle priorité deviendra {4:D}, {3:E}, {2:B}
- Put (touche 1, valeur A) : Puisque notre cache est COMPLET, utilisez donc notre algorithme LRU pour déterminer quelle clé a été utilisée la moins récemment, et puisque {2:B} avait la moindre priorité, supprimez {2:B} de notre cache et placez {1:A} dans le cache. Désormais, le nouvel ordre de priorité est {1:A}, {4:D}, {3:E}.
Façons d’implémenter le cache LRU :
Le cache LRU peut être implémenté de différentes manières et chaque programmeur peut choisir une approche différente. Cependant, vous trouverez ci-dessous les approches couramment utilisées :
- LRU utilisant la file d'attente et le hachage
- LRU utilisant Liste doublement chaînée + hachage
- LRU utilisant Deque
- LRU utilisant Stack
- LRU utilisant Mise en œuvre du compteur
- LRU utilisant des mises à jour paresseuses
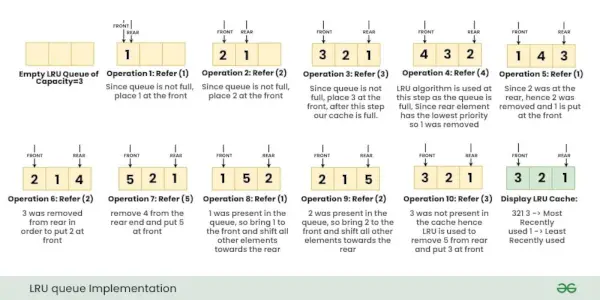
Implémentation du cache LRU à l'aide de la file d'attente et du hachage :
Nous utilisons deux structures de données pour implémenter un cache LRU.
comment lire un fichier csv en java
- File d'attente est implémenté à l’aide d’une liste doublement chaînée. La taille maximale de la file d'attente sera égale au nombre total de frames disponibles (taille du cache). Les pages les plus récemment utilisées se trouveront près de la partie avant et les pages les moins récemment utilisées se trouveront près de la partie arrière.
- Un hachage avec le numéro de page comme clé et l'adresse du nœud de file d'attente correspondant comme valeur.
Lorsqu'une page est référencée, la page requise peut être en mémoire. S'il est en mémoire, nous devons détacher le nœud de la liste et le placer en tête de la file d'attente.
Si la page requise n'est pas en mémoire, nous la mettons en mémoire. En termes simples, nous ajoutons un nouveau nœud au début de la file d'attente et mettons à jour l'adresse du nœud correspondant dans le hachage. Si la file d'attente est pleine, c'est-à-dire que toutes les trames sont pleines, nous supprimons un nœud à l'arrière de la file d'attente et ajoutons le nouveau nœud à l'avant de la file d'attente.
Illustration:
Considérons les opérations, Fait référence clé X avec dans le cache LRU : { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Note: Au départ, aucune page n'est en mémoire.Les images ci-dessous montrent l'exécution étape par étape des opérations ci-dessus sur le cache LRU.
Algorithme:
- Créez une classe LRUCache en déclarant une liste de type int, une carte non ordonnée de type
- Dans la fonction de référence de LRUCache
- Si cette valeur n'est pas présente dans la file d'attente alors placez cette valeur devant la file d'attente et supprimez la dernière valeur si la file d'attente est pleine
- Si la valeur est déjà présente, supprimez-la de la file d'attente et placez-la au début de la file d'attente.
- Dans la fonction d'affichage imprimer, le LRUCache utilise la file d'attente en commençant par l'avant
Vous trouverez ci-dessous la mise en œuvre de l’approche ci-dessus :
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>qq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::itérateur> ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->numéro de page = numéro de page ;> > >// Initialize prev and next as NULL> >temp->prev = temp->next = NULL ;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->compte = 0 ;> >queue->front = file d'attente->arrière = NULL ;> > >// Number of frames that can be stored in memory> >queue->nombreOfFrames = nombreOfFrames;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->capacité = capacité ;> > >// Create an array of pointers for referring queue nodes> >hash->tableau> >= (QNode**)>malloc>(hash->capacité *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->tableau[i] = NULL ;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->count == file d'attente->numberOfFrames ;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->arrière == NULL ;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->avant == file d'attente->arrière)> >queue->devant = NULL ;> > >// Change rear and remove the previous rear> >QNode* temp = queue->arrière;> >queue->arrière = file d'attente->arrière->préc;> > >if> (queue->arrière)> >queue->arrière->suivant = NULL ;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->compter--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->array[queue->rear->pageNumber] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->suivant = file d'attente->front;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->arrière = file d'attente->avant = temp;> >else> // Else change the front> >{> >queue->front->prev = temp;> >queue->avant = température ;> >}> > >// Add page entry to hash also> >hash->tableau[pageNumber] = temp;> > >// increment number of full frames> >queue->compte++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->tableau[numéro de page];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->recto) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->précédent->suivant = reqPage->suivant ;> >if> (reqPage->suivant)> >reqPage->suivant->prev = reqPage->prev;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->arrière) {> >queue->arrière = reqPage->préc;> >queue->arrière->suivant = NULL ;> >}> > >// Put the requested page before current front> >reqPage->suivant = file d'attente->front;> >reqPage->précédent = NULL ;> > >// Change prev of current front> >reqPage->suivant->préc = reqPage;> > >// Change front to the requested page> >queue->front = reqPage;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->front->pageNumber);> >printf>(>'%d '>, q->avant->suivant->pageNumber);> >printf>(>'%d '>, q->avant->suivant->suivant->pageNumber);> >printf>(>'%d '>, q->avant->suivant->suivant->suivant->pageNumber);> > >return> 0;> }> |
>
>
Java
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
dépendance partielle
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>doublementQueue ;> > >// store references of key in cache> >private> HashSet<>int>>hashSet;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
Implémentation du cache LRU à l'aide de la liste doublement liée et du hachage :
L'idée est très basique, c'est à dire continuer à insérer les éléments en tête.
- si l'élément n'est pas présent dans la liste alors ajoutez-le en tête de liste
- si l'élément est présent dans la liste, déplacez l'élément vers la tête et décalez l'élément restant de la liste
Notez que la priorité du nœud dépendra de la distance de ce nœud par rapport à la tête, plus le nœud est proche de la tête, plus sa priorité est élevée. Ainsi, lorsque la taille du cache est pleine et que nous devons supprimer un élément, nous supprimons l'élément adjacent à la queue de la liste doublement chaînée.
Implémentation du cache LRU à l'aide de Deque & Hashmap :
La structure de données Deque permet l'insertion et la suppression depuis l'avant comme vers la fin, cette propriété permet l'implémentation de LRU possible car l'élément Front peut représenter un élément de haute priorité tandis que l'élément de fin peut être l'élément de faible priorité, c'est-à-dire le moins récemment utilisé.
Fonctionnement:
- Obtenir l'opération : Vérifie si la clé existe dans la carte de hachage du cache et suit les cas ci-dessous sur le deque :
- Si la clé est trouvée :
- L'article est considéré comme récemment utilisé, il est donc déplacé vers l'avant du deque.
- La valeur associée à la clé est renvoyée comme résultat de la
get>opération.- Si la clé n'est pas trouvée :
- renvoie -1 pour indiquer qu'aucune clé de ce type n'est présente.
- Opération de mise : Vérifiez d’abord si la clé existe déjà dans la carte de hachage du cache et suivez les cas ci-dessous sur le deque
- Si la clé existe :
- La valeur associée à la clé est mise à jour.
- L’élément est déplacé vers l’avant du deque puisqu’il s’agit désormais du dernier utilisé.
- Si la clé n'existe pas :
- Si le cache est plein, cela signifie qu'un nouvel élément doit être inséré et que l'élément le moins récemment utilisé doit être expulsé. Cela se fait en supprimant l'élément de la fin du deque et l'entrée correspondante de la carte de hachage.
- La nouvelle paire clé-valeur est ensuite insérée à la fois dans la carte de hachage et au début du deque pour signifier qu'il s'agit de l'élément le plus récemment utilisé.
Implémentation du cache LRU à l'aide de Stack & Hashmap :
La mise en œuvre d'un cache LRU (Least Récemment Utilisé) à l'aide d'une structure de données de pile et d'un hachage peut être un peu délicate, car une simple pile ne fournit pas un accès efficace à l'élément le moins récemment utilisé. Cependant, vous pouvez combiner une pile avec une carte de hachage pour y parvenir efficacement. Voici une approche de haut niveau pour le mettre en œuvre :
- Utiliser une carte de hachage : La carte de hachage stockera les paires clé-valeur du cache. Les clés seront mappées aux nœuds correspondants dans la pile.
- Utiliser une pile : La pile conservera l'ordre des clés en fonction de leur utilisation. L'élément le moins récemment utilisé sera en bas de la pile et l'élément le plus récemment utilisé sera en haut.
Cette approche n’est pas très efficace et n’est donc pas souvent utilisée.
Cache LRU à l'aide de l'implémentation de compteur :
Chaque bloc du cache aura son propre compteur LRU auquel appartient la valeur du compteur. {0 à n-1} , ici ' n ' représente la taille du cache. Le bloc modifié lors du remplacement de bloc devient le bloc MRU et, par conséquent, sa valeur de compteur passe à n – 1. Les valeurs de compteur supérieures à la valeur de compteur du bloc accédé sont décrémentées de un. Les blocs restants ne sont pas modifiés.
| Valeur du compteur | Priorité | Statut utilisé |
|---|---|---|
| 0 | Faible | Le moins récemment utilisé chaînage avant |
| n-1 | Haut | Utilisé le plus récemment |
Implémentation du cache LRU à l'aide des mises à jour différées :
La mise en œuvre d'un cache LRU (Least Récemment Utilisé) à l'aide de mises à jour différées est une technique courante pour améliorer l'efficacité des opérations du cache. Les mises à jour paresseuses impliquent de suivre l'ordre dans lequel les éléments sont accédés sans mettre à jour immédiatement l'intégralité de la structure des données. Lorsqu'un échec de cache se produit, vous pouvez alors décider d'effectuer ou non une mise à jour complète en fonction de certains critères.
Analyse de la complexité du cache LRU :
- Complexité temporelle :
- Opération Put() : O(1), c'est-à-dire que le temps requis pour insérer ou mettre à jour une nouvelle paire clé-valeur est constant
- Opération Get() : O(1), c'est-à-dire que le temps requis pour obtenir la valeur d'une clé est constant
- Espace auxiliaire : O(N) où N est la capacité du Cache.
Avantages du cache LRU :
- Accès rapide : Il faut un temps O(1) pour accéder aux données du cache LRU.
- Mise à jour rapide : Il faut un temps O(1) pour mettre à jour une paire clé-valeur dans le cache LRU.
- Suppression rapide des données les moins récemment utilisées : Il faut O(1) supprimer ce qui n’a pas été utilisé récemment.
- Pas de raclée : LRU est moins susceptible d'être battu que FIFO car il prend en compte l'historique d'utilisation des pages. Il peut détecter quelles pages sont fréquemment utilisées et les hiérarchiser pour l'allocation de mémoire, réduisant ainsi le nombre de défauts de page et d'opérations d'E/S disque.
Inconvénients du cache LRU :
- Cela nécessite une grande taille de cache pour augmenter l’efficacité.
- Cela nécessite la mise en œuvre d’une structure de données supplémentaire.
- L’assistance matérielle est élevée.
- Dans LRU, la détection des erreurs est difficile par rapport à d’autres algorithmes.
- Son acceptabilité est limitée.
Application réelle du cache LRU :
- Dans les systèmes de base de données pour des résultats de requête rapides.
- Dans les systèmes d'exploitation pour minimiser les défauts de page.
- Éditeurs de texte et IDE pour stocker les fichiers ou les extraits de code fréquemment utilisés
- Les routeurs et commutateurs réseau utilisent LRU pour augmenter l'efficacité du réseau informatique
- Dans les optimisations du compilateur
- Outils de prédiction de texte et de saisie semi-automatique