Depuis l'invention des ordinateurs, les gens utilisent le terme « » Données ' pour faire référence aux informations informatiques, transmises ou stockées. Cependant, certaines données existent également dans les types de commandes. Les données peuvent être des nombres ou des textes écrits sur un morceau de papier, sous forme de bits et d'octets stockés dans la mémoire d'appareils électroniques, ou des faits stockés dans l'esprit d'une personne. À mesure que le monde commençait à se moderniser, ces données sont devenues un aspect important de la vie quotidienne de chacun, et diverses implémentations leur ont permis de les stocker différemment.
Données est une collection de faits et de chiffres ou un ensemble de valeurs ou de valeurs d'un format spécifique qui fait référence à un seul ensemble de valeurs d'éléments. Les éléments de données sont ensuite classés en sous-éléments, qui constituent le groupe d'éléments qui ne sont pas connus comme la forme principale simple de l'élément.
Prenons un exemple dans lequel le nom d'un employé peut être décomposé en trois sous-éléments : premier, deuxième et dernier. Cependant, une pièce d'identité attribuée à un employé sera généralement considérée comme un seul élément.
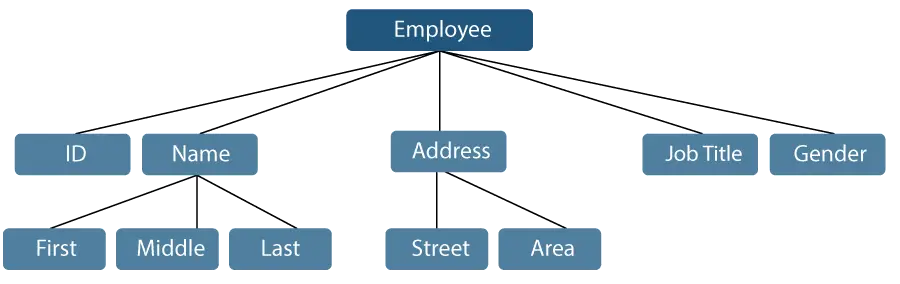
Figure 1: Représentation des éléments de données
Dans l'exemple mentionné ci-dessus, les éléments tels que pièce d'identité, âge, sexe, prénom, deuxième prénom, dernier nom, rue, localité, etc., sont des éléments de données élémentaires. En revanche, le Nom et l'Adresse sont des données de groupe.
Qu’est-ce que la structure des données ?
Structure de données est une branche de l'informatique. L'étude de la structure des données nous permet de comprendre l'organisation des données et la gestion du flux de données afin d'augmenter l'efficacité de tout processus ou programme. La structure des données est une manière particulière de stocker et d'organiser les données dans la mémoire de l'ordinateur afin que ces données puissent être facilement récupérées et utilisées efficacement à l'avenir en cas de besoin. Les données peuvent être gérées de différentes manières, comme le modèle logique ou mathématique d'une organisation spécifique de données est appelé structure de données.
La portée d'un modèle de données particulier dépend de deux facteurs :
- Premièrement, il doit être suffisamment chargé dans la structure pour refléter la corrélation définie des données avec un objet du monde réel.
- Deuxièmement, la formation doit être si simple que l'on puisse s'adapter pour traiter les données efficacement chaque fois que cela est nécessaire.
Quelques exemples de structures de données sont les tableaux, les listes chaînées, la pile, la file d'attente, les arbres, etc. Les structures de données sont largement utilisées dans presque tous les aspects de l'informatique, c'est-à-dire la conception de compilateurs, les systèmes d'exploitation, les graphiques, l'intelligence artificielle et bien d'autres.
Les structures de données constituent la partie principale de nombreux algorithmes informatiques car elles permettent aux programmeurs de gérer les données de manière efficace. Il joue un rôle crucial dans l'amélioration des performances d'un programme ou d'un logiciel, car l'objectif principal du logiciel est de stocker et de récupérer les données de l'utilisateur le plus rapidement possible.
java création d'une liste
Terminologies de base liées aux structures de données
Les structures de données sont les éléments constitutifs de tout logiciel ou programme. La sélection de la structure de données appropriée pour un programme est une tâche extrêmement difficile pour un programmeur.
Voici quelques terminologies fondamentales utilisées chaque fois que les structures de données sont impliquées :
| Les attributs | IDENTIFIANT | Nom | Genre | Titre d'emploi |
|---|---|---|---|---|
| Valeurs | 1234 | Stacey M. Hill | Femelle | Développeur de logiciels |
Les entités ayant des attributs similaires forment un Ensemble d'entités . Chaque attribut d'un ensemble d'entités possède une plage de valeurs, l'ensemble de toutes les valeurs possibles qui pourraient être attribuées à l'attribut spécifique.
Le terme « information » est parfois utilisé pour désigner des données ayant des attributs donnés de données significatives ou traitées.
Comprendre le besoin de structures de données
À mesure que les applications deviennent plus complexes et que la quantité de données augmente chaque jour, cela peut entraîner des problèmes de recherche de données, de vitesse de traitement, de traitement de demandes multiples, et bien d'autres encore. Les structures de données prennent en charge différentes méthodes pour organiser, gérer et stocker efficacement les données. Avec l'aide des structures de données, nous pouvons facilement parcourir les éléments de données. Les structures de données offrent efficacité, réutilisabilité et abstraction.
Pourquoi devrions-nous apprendre les structures de données ?
- Les structures de données et les algorithmes sont deux des aspects clés de l'informatique.
- Les structures de données nous permettent d'organiser et de stocker des données, tandis que les algorithmes nous permettent de traiter ces données de manière significative.
- L'apprentissage des structures de données et des algorithmes nous aidera à devenir de meilleurs programmeurs.
- Nous pourrons écrire du code plus efficace et plus fiable.
- Nous serons également en mesure de résoudre les problèmes plus rapidement et plus efficacement.
Comprendre les objectifs des structures de données
Les Structures de Données répondent à deux objectifs complémentaires :
Comprendre certaines fonctionnalités clés des structures de données
Certaines des caractéristiques importantes des structures de données sont :
Classification des structures de données
Une structure de données fournit un ensemble structuré de variables liées les unes aux autres de différentes manières. Il constitue la base d'un outil de programmation qui représente la relation entre les éléments de données et permet aux programmeurs de traiter les données efficacement.
Nous pouvons classer les structures de données en deux catégories :
- Structure de données primitive
- Structure de données non primitive
La figure suivante montre les différentes classifications des structures de données.

Figure 2: Classifications des structures de données
Structures de données primitives
- Ces structures de données peuvent être manipulées ou exploitées directement par des instructions au niveau machine.
- Types de données de base comme Entier, flottant, caractère , et Booléen relèvent des structures de données primitives.
- Ces types de données sont également appelés Types de données simples , car ils contiennent des caractères qui ne peuvent pas être divisés davantage
Structures de données non primitives
- Ces structures de données ne peuvent pas être manipulées ou exploitées directement par des instructions au niveau machine.
- L'objectif de ces structures de données est de former un ensemble d'éléments de données qui sont soit homogène (même type de données) ou hétérogène (différents types de données).
- Sur la base de la structure et de la disposition des données, nous pouvons diviser ces structures de données en deux sous-catégories :
- Structures de données linéaires
- Structures de données non linéaires
Structures de données linéaires
Une structure de données qui préserve une connexion linéaire entre ses éléments de données est appelée structure de données linéaire. L'agencement des données se fait de manière linéaire, chaque élément étant constitué des successeurs et des prédécesseurs à l'exception du premier et du dernier élément de données. Cependant, cela n'est pas nécessairement vrai dans le cas de la mémoire, car l'agencement peut ne pas être séquentiel.
Sur la base de l'allocation de mémoire, les structures de données linéaires sont en outre classées en deux types :
Le Tableau est le meilleur exemple de structure de données statique car elles ont une taille fixe et ses données peuvent être modifiées ultérieurement.
Listes liées, piles , et Queues sont des exemples courants de structures de données dynamiques
Types de structures de données linéaires
Voici la liste des structures de données linéaires que nous utilisons généralement :
1. Tableaux
Un Tableau est une structure de données utilisée pour collecter plusieurs éléments de données du même type de données dans une seule variable. Au lieu de stocker plusieurs valeurs des mêmes types de données dans des noms de variables distincts, nous pourrions toutes les stocker ensemble dans une seule variable. Cette déclaration n'implique pas que nous devrons réunir toutes les valeurs du même type de données dans n'importe quel programme en un seul tableau de ce type de données. Mais il y aura souvent des moments où certaines variables spécifiques des mêmes types de données seront toutes liées les unes aux autres d'une manière appropriée pour un tableau.
Un tableau est une liste d'éléments où chaque élément a une place unique dans la liste. Les éléments de données du tableau partagent le même nom de variable ; cependant, chacun porte un numéro d’index différent appelé indice. Nous pouvons accéder à n'importe quel élément de données de la liste à l'aide de son emplacement dans la liste. Ainsi, la principale caractéristique des tableaux à comprendre est que les données sont stockées dans des emplacements de mémoire contigus, permettant aux utilisateurs de parcourir les éléments de données du tableau en utilisant leurs index respectifs.

Figure 3. Un tableau
c booléen
Les tableaux peuvent être classés en différents types :
Quelques applications du tableau :
- Nous pouvons stocker une liste d'éléments de données appartenant au même type de données.
- Array agit comme un stockage auxiliaire pour d’autres structures de données.
- Le tableau permet également de stocker les éléments de données d'un arbre binaire du nombre fixe.
- Array agit également comme un stockage de matrices.
2. Listes liées
UN Liste liée est un autre exemple de structure de données linéaire utilisée pour stocker dynamiquement une collection d’éléments de données. Les éléments de données de cette structure de données sont représentés par les nœuds, connectés à l'aide de liens ou de pointeurs. Chaque nœud contient deux champs, le champ d'information est constitué des données réelles et le champ de pointeur est constitué de l'adresse des nœuds suivants dans la liste. Le pointeur du dernier nœud de la liste chaînée est constitué d’un pointeur nul, car il ne pointe vers rien. Contrairement aux tableaux, l'utilisateur peut ajuster dynamiquement la taille d'une liste liée selon les exigences.

Graphique 4. Une liste chaînée
Les listes liées peuvent être classées en différents types :
Quelques applications des listes chaînées :
- Les listes chaînées nous aident à implémenter des piles, des files d'attente, des arbres binaires et des graphiques de taille prédéfinie.
- Nous pouvons également implémenter la fonction du système d'exploitation pour la gestion dynamique de la mémoire.
- Les listes liées permettent également une implémentation polynomiale pour les opérations mathématiques.
- Nous pouvons utiliser la liste chaînée circulaire pour implémenter des systèmes d'exploitation ou des fonctions d'application qui exécutent des tâches à tour de rôle.
- La liste chaînée circulaire est également utile dans un diaporama où un utilisateur doit revenir à la première diapositive après la présentation de la dernière diapositive.
- La liste doublement liée est utilisée pour implémenter des boutons avant et arrière dans un navigateur pour avancer et reculer dans les pages ouvertes d'un site Web.
3. Piles
UN Empiler est une structure de données linéaire qui suit le LIFO (Last In, First Out) qui permet des opérations telles que l'insertion et la suppression à partir d'une extrémité de la pile, c'est-à-dire Top. Les piles peuvent être implémentées à l'aide d'une mémoire contiguë, un tableau, et d'une mémoire non contiguë, une liste chaînée. Des exemples concrets de Stacks sont des piles de livres, un jeu de cartes, des piles d'argent et bien d'autres.

Graphique 5. Un exemple concret de pile
La figure ci-dessus représente l'exemple réel d'une pile où les opérations sont effectuées à partir d'une seule extrémité, comme l'insertion et le retrait de nouveaux livres du haut de la pile. Cela implique que l'insertion et la suppression dans la pile ne peuvent être effectuées qu'à partir du haut de la pile. Nous ne pouvons accéder qu'aux sommets de la Stack à tout moment.
Les principales opérations dans la pile sont les suivantes :

Graphique 6. Une pile
âge de Vicky Kaushal
Quelques applications des piles :
- La pile est utilisée comme structure de stockage temporaire pour les opérations récursives.
- Stack est également utilisé comme structure de stockage auxiliaire pour les appels de fonctions, les opérations imbriquées et les fonctions différées/reportées.
- Nous pouvons gérer les appels de fonction à l'aide de Stacks.
- Les piles sont également utilisées pour évaluer les expressions arithmétiques dans différents langages de programmation.
- Les piles sont également utiles pour convertir des expressions infixes en expressions postfixes.
- Les piles nous permettent de vérifier la syntaxe de l'expression dans l'environnement de programmation.
- Nous pouvons faire correspondre les parenthèses en utilisant Stacks.
- Les piles peuvent être utilisées pour inverser une chaîne.
- Les piles sont utiles pour résoudre des problèmes basés sur le retour en arrière.
- Nous pouvons utiliser Stacks dans une recherche approfondie d'abord dans le parcours de graphiques et d'arbres.
- Les piles sont également utilisées dans les fonctions du système d'exploitation.
- Les piles sont également utilisées dans les fonctions UNDO et REDO lors d'une édition.
4. Queues
UN File d'attente est une structure de données linéaire similaire à une pile avec quelques limitations sur l'insertion et la suppression des éléments. L'insertion d'un élément dans une file d'attente se fait à une extrémité, et la suppression se fait à une autre extrémité ou à l'autre extrémité. Ainsi, nous pouvons conclure que la structure de données de la file d'attente suit le principe FIFO (First In, First Out) pour manipuler les éléments de données. L'implémentation des files d'attente peut être effectuée à l'aide de tableaux, de listes liées ou de piles. Quelques exemples concrets de files d'attente sont une file d'attente au guichet, un escalier roulant, un lave-auto et bien d'autres encore.

Graphique 7. Un exemple concret de file d'attente
L'image ci-dessus est une illustration réelle d'un guichet de cinéma qui peut nous aider à comprendre la file d'attente où le client qui arrive en premier est toujours servi en premier. Le client arrivé en dernier sera sans aucun doute servi en dernier. Les deux extrémités de la file d'attente sont ouvertes et peuvent exécuter différentes opérations. Un autre exemple est une ligne d'aire de restauration où le client est inséré par l'arrière tandis que le client est retiré à l'avant après avoir fourni le service qu'il a demandé.
Voici les principales opérations de la file d'attente :

Figure 8. File d'attente
Quelques applications des files d'attente :
- Les files d'attente sont généralement utilisées dans l'opération de recherche étendue dans les graphiques.
- Les files d'attente sont également utilisées dans les opérations du planificateur de tâches des systèmes d'exploitation, comme une file d'attente de tampon de clavier pour stocker les touches enfoncées par les utilisateurs et une file d'attente de tampon d'impression pour stocker les documents imprimés par l'imprimante.
- Les files d'attente sont responsables de la planification du processeur, de la planification des tâches et de la planification des disques.
- Les files d'attente prioritaires sont utilisées dans les opérations de téléchargement de fichiers dans un navigateur.
- Les files d'attente sont également utilisées pour transférer des données entre les périphériques et le processeur.
- Les files d'attente sont également responsables de la gestion des interruptions générées par les applications utilisateur pour le processeur.
Structures de données non linéaires
Les structures de données non linéaires sont des structures de données dans lesquelles les éléments de données ne sont pas disposés dans un ordre séquentiel. Ici, l'insertion et la suppression de données ne sont pas réalisables de manière linéaire. Il existe une relation hiérarchique entre les éléments de données individuels.
Types de structures de données non linéaires
Voici la liste des structures de données non linéaires que nous utilisons généralement :
1. Arbres
Un arbre est une structure de données non linéaire et une hiérarchie contenant une collection de nœuds tels que chaque nœud de l'arborescence stocke une valeur et une liste de références à d'autres nœuds (les « enfants »).
La structure de données arborescente est une méthode spécialisée pour organiser et collecter des données dans l'ordinateur afin de les utiliser plus efficacement. Il contient un nœud central, des nœuds structurels et des sous-nœuds connectés via des bords. On peut également dire que la structure de données arborescente est constituée de racines, de branches et de feuilles connectées.

Graphique 9. Un arbre
Les arbres peuvent être classés en différents types :
Quelques applications des arbres :
caractéristiques d'une série panda
- Les arbres implémentent des structures hiérarchiques dans les systèmes informatiques tels que les répertoires et les systèmes de fichiers.
- Les arbres sont également utilisés pour mettre en œuvre la structure de navigation d’un site Web.
- Nous pouvons générer du code comme celui de Huffman en utilisant des arbres.
- Les arbres sont également utiles à la prise de décision dans les applications de jeux.
- Les arborescences sont responsables de la mise en œuvre des files d'attente prioritaires pour les fonctions de planification du système d'exploitation basées sur les priorités.
- Les arbres sont également responsables de l'analyse des expressions et des instructions dans les compilateurs de différents langages de programmation.
- Nous pouvons utiliser des arbres pour stocker des clés de données à indexer pour le système de gestion de base de données (SGBD).
- Les Spanning Trees nous permettent d'acheminer les décisions dans les réseaux informatiques et de communication.
- Les arbres sont également utilisés dans l'algorithme de recherche de chemin implémenté dans les applications d'intelligence artificielle (IA), de robotique et de jeux vidéo.
2. Graphiques
Un graphique est un autre exemple de structure de données non linéaire comprenant un nombre fini de nœuds ou de sommets et les arêtes qui les relient. Les graphiques sont utilisés pour résoudre les problèmes du monde réel dans lesquels ils désignent la zone problématique en tant que réseau tel que les réseaux sociaux, les réseaux de circuits et les réseaux téléphoniques. Par exemple, les nœuds ou sommets d'un graphique peuvent représenter un seul utilisateur dans un réseau téléphonique, tandis que les bords représentent le lien entre eux via le téléphone.
La structure de données Graph, G est considérée comme une structure mathématique composée d'un ensemble de sommets, V et d'un ensemble d'arêtes, E, comme indiqué ci-dessous :
G = (V,E)

Graphique 10. Un graphique
La figure ci-dessus représente un graphique ayant sept sommets A, B, C, D, E, F, G et dix arêtes [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] et [E, G].
En fonction de la position des sommets et des arêtes, les graphiques peuvent être classés en différents types :
Quelques applications des graphiques :
remplacer une chaîne en Java
- Les graphiques nous aident à représenter les itinéraires et les réseaux dans les applications de transport, de voyage et de communication.
- Les graphiques sont utilisés pour afficher les itinéraires dans le GPS.
- Les graphiques nous aident également à représenter les interconnexions dans les réseaux sociaux et autres applications basées sur les réseaux.
- Les graphiques sont utilisés dans les applications de cartographie.
- Les graphiques sont responsables de la représentation des préférences des utilisateurs dans les applications de commerce électronique.
- Les graphiques sont également utilisés dans les réseaux de services publics afin d'identifier les problèmes posés aux entreprises locales ou municipales.
- Les graphiques aident également à gérer l'utilisation et la disponibilité des ressources dans une organisation.
- Des graphiques sont également utilisés pour créer des cartes de liens vers des documents des sites Web afin d'afficher la connectivité entre les pages via des hyperliens.
- Les graphiques sont également utilisés dans les mouvements robotiques et les réseaux neuronaux.
Opérations de base des structures de données
Dans la section suivante, nous aborderons les différents types d'opérations que nous pouvons effectuer pour manipuler des données dans chaque structure de données :
- Au moment de la compilation
- Durée
Par exemple, le malloc() La fonction est utilisée en langage C pour créer une structure de données.
Comprendre le type de données abstrait
Selon le Institut national des normes et de la technologie (NIST) , une structure de données est un arrangement d'informations, généralement dans la mémoire, pour une meilleure efficacité de l'algorithme. Les structures de données incluent des listes chaînées, des piles, des files d'attente, des arborescences et des dictionnaires. Il peut également s'agir d'une entité théorique, comme le nom et l'adresse d'une personne.
De la définition mentionnée ci-dessus, nous pouvons conclure que les opérations dans la structure des données comprennent :
- Un niveau élevé d'abstractions comme l'ajout ou la suppression d'un élément d'une liste.
- Rechercher et trier un élément dans une liste.
- Accéder à l'élément le plus prioritaire dans une liste.
Chaque fois que la structure de données effectue de telles opérations, on parle de Type de données abstrait (ADT) .
Nous pouvons le définir comme un ensemble d'éléments de données ainsi que les opérations sur les données. Le terme « abstrait » fait référence au fait que les données et les opérations fondamentales qui y sont définies sont étudiées indépendamment de leur mise en œuvre. Cela inclut ce que nous pouvons faire avec les données, et non la manière dont nous pouvons le faire.
Une implémentation ADI contient une structure de stockage afin de stocker les éléments de données et les algorithmes pour le fonctionnement fondamental. Toutes les structures de données, comme un tableau, une liste chaînée, une file d'attente, une pile, etc., sont des exemples d'ADT.
Comprendre les avantages de l'utilisation des ADT
Dans le monde réel, les programmes évoluent en conséquence de nouvelles contraintes ou exigences, donc la modification d'un programme nécessite généralement un changement dans une ou plusieurs structures de données. Par exemple, supposons que nous souhaitions insérer un nouveau champ dans le dossier d'un employé pour conserver plus de détails sur chaque employé. Dans ce cas, nous pouvons améliorer l'efficacité du programme en remplaçant un Array par une structure Linked. Dans une telle situation, réécrire chaque procédure utilisant la structure modifiée n’est pas approprié. Par conséquent, une meilleure alternative consiste à séparer une structure de données de ses informations de mise en œuvre. C'est le principe derrière l'utilisation des types de données abstraits (ADT).
Quelques applications des structures de données
Voici quelques applications des structures de données :
- Les structures de données aident à l'organisation des données dans la mémoire d'un ordinateur.
- Les structures de données aident également à représenter les informations dans les bases de données.
- Les structures de données permettent la mise en œuvre d'algorithmes pour rechercher dans les données (par exemple, moteur de recherche).
- Nous pouvons utiliser les structures de données pour implémenter les algorithmes permettant de manipuler les données (par exemple, des traitements de texte).
- Nous pouvons également mettre en œuvre des algorithmes pour analyser les données à l'aide de structures de données (par exemple, des mineurs de données).
- Les structures de données prennent en charge des algorithmes pour générer les données (par exemple, un générateur de nombres aléatoires).
- Les structures de données prennent également en charge des algorithmes pour compresser et décompresser les données (par exemple, un utilitaire zip).
- Nous pouvons également utiliser des structures de données pour mettre en œuvre des algorithmes permettant de crypter et déchiffrer les données (par exemple, un système de sécurité).
- Avec l'aide des structures de données, nous pouvons créer un logiciel capable de gérer des fichiers et des répertoires (par exemple, un gestionnaire de fichiers).
- Nous pouvons également développer des logiciels capables de restituer des graphiques à l’aide de structures de données. (Par exemple, un navigateur Web ou un logiciel de rendu 3D).
En dehors de celles-ci, comme mentionné précédemment, il existe de nombreuses autres applications de structures de données qui peuvent nous aider à créer n'importe quel logiciel souhaité.