La commande Linux uniq est utilisée pour supprimer toutes les lignes répétées d'un fichier. En outre, il peut être utilisé pour afficher le nombre de mots, uniquement les lignes répétées, ignorer les caractères et comparer des champs spécifiques. C'est l'une des commandes les plus fréquemment utilisées dans le Linux système. Il est souvent utilisé avec le commande de tri car il compare les caractères adjacents. Il supprime toutes les lignes identiques et écrit la sortie.
Syntaxe:
uniq [OPTION]... [INPUT [OUTPUT]]
Possibilités :
Certaines options de ligne de commande utiles de la commande uniq sont les suivantes :
-c, --compte : il préfixe les lignes par le nombre d'occurrences.
-d, --répété : il est utilisé pour imprimer des lignes en double, une pour chaque groupe.
-D: Il est utilisé pour imprimer toutes les lignes en double.
--all-repeated[=MÉTHODE] : C'est assez similaire à l'option '-D', la différence entre les deux options est qu'elle permet la séparation des groupes avec une ligne vide.
-f, --skip-fields=N : Il est utilisé pour éviter la comparaison des N premiers champs.
--group[=MÉTHODE] : Il permet d'afficher tous les éléments et sépare les groupes par une ligne vide.
récursion java
-i, --ignore-case : Il est utilisé pour ignorer les différences lors de la comparaison.
-s, --skip-chars=N : Il permet d'éviter la comparaison des N premiers caractères.
-u, --unique : il est utilisé pour imprimer des lignes uniques.
-z, --terminé par zéro : Il est utilisé pour que le délimiteur de ligne soit NUL et non en mode nouvelle ligne.
-w, --check-chars=N : Il est utilisé pour comparer pas plus de N caractères dans des lignes.
--aide: Il est utilisé pour afficher la documentation d'aide.
--version: Il est utilisé pour afficher les informations de version.
Exemples de commande uniq
Voyons les exemples suivants de la commande uniq :
- Supprimer les lignes répétées
- compter le nombre d'occurrences d'un mot
- Afficher les lignes répétées
- Afficher les lignes uniques
- Ignorer les caractères en comparaison
- Ignorer les champs dans la comparaison
Supprimer les lignes répétées
Pour supprimer les lignes répétées d'un fichier, exécutez la commande uniq de base comme suit :
préparer le test mockito
sort dupli.txt | uniq
La commande ci-dessus supprimera les lignes en double du fichier « dupli.txt ». Considérez le résultat ci-dessous :
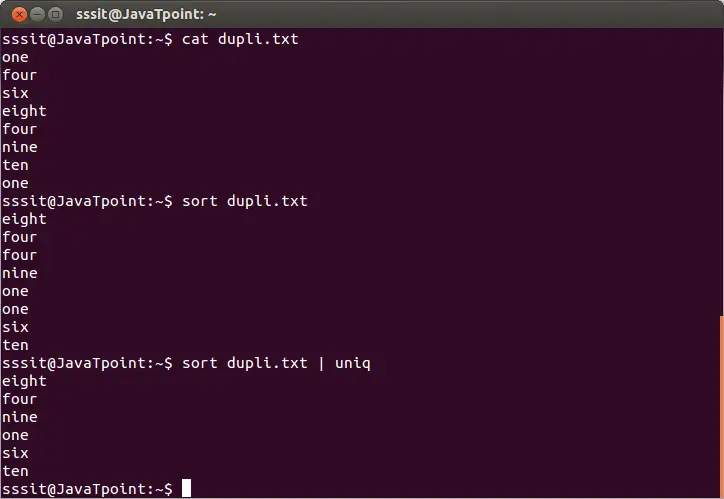
À partir de la sortie ci-dessus, les mots répétitifs sont ignorés.
Compter le nombre d'occurrences d'un mot
Nous pouvons compter le nombre d'occurrences d'un mot en utilisant la commande uniq. L'option '-c' est utilisée pour compter le mot. Exécutez-le comme suit :
sort dupli.txt | uniq -c
La commande ci-dessus comptera les mots qui entrent dans 'dupli.txt'. Considérez le résultat ci-dessous :
commutateur dactylographié

À partir de la sortie ci-dessus, la commande « sort dupli.txt | uniq -c' compte le nombre de fois qu'un mot est répété.
Afficher les lignes répétées
L'option '-d' est utilisée pour afficher uniquement les lignes répétées. Il affichera uniquement les lignes qui figureront plus d'une fois dans un fichier et écrira la sortie sur la sortie standard. Considérez la commande ci-dessous :
sort dupli.txt | uniq -d
La commande ci-dessus affichera uniquement les lignes répétées. Considérez le résultat ci-dessous :

Afficher les lignes uniques
L'option '-u' permet d'afficher uniquement les lignes uniques (qui ne sont pas répétées). Il affichera uniquement les lignes qui n'apparaissent qu'une seule fois et écrira le résultat sur la sortie standard. Considérez la commande ci-dessous :
sort dupli.txt | uniq -u
La commande ci-dessus affichera uniquement les lignes uniques du fichier « dupli.txt ». Considérez le résultat ci-dessous :

Ignorer les caractères en comparaison
L'option '-s' est utilisée pour ignorer les caractères en comparaison. Il ignorera le nombre de caractères spécifié et affichera le résultat sur la sortie standard. Considérez la commande ci-dessous :
sort dupli.txt | uniq -s 2
La commande ci-dessus ignorera les deux premiers caractères par rapport au fichier « dupli.txt ». Considérez le résultat ci-dessous :

Ignorer les champs dans la comparaison
L'option '-f' est utilisée pour ignorer les champs. Considérez la commande ci-dessous :
uniq -f 2 dupli2.txt
La commande ci-dessus ne comparera pas les deux premiers champs du fichier 'dupli2.txt'. Considérez le résultat ci-dessous :

À partir de la sortie ci-dessus, les deux premiers champs sont ignorés et le reste de tous les champs est comparé à partir du fichier « dupli2.txt ».