Dans cet article, nous verrons comment ajouter une nouvelle ligne de valeurs à un dataframe existant. Cela peut être utilisé lorsque nous souhaitons insérer une nouvelle entrée dans nos données que nous aurions peut-être manqué d'ajouter plus tôt. Il existe différentes méthodes pour y parvenir.
Voyons maintenant à l'aide d'exemples comment procéder.
Exemple 1:
Nous pouvons ajouter une seule ligne en utilisant DataFrame.loc . Nous pouvons ajouter la ligne en dernier lieu dans notre dataframe. Nous pouvons obtenir le nombre de lignes en utilisant len(DataFrame.index) pour déterminer la position à laquelle nous devons ajouter la nouvelle ligne.
Python from IPython.display import display, HTML import pandas as pd from numpy.random import randint dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'], 'Maths':[87, 91, 97, 95], 'Science':[83, 99, 84, 76] } df = pd.DataFrame(dict) display(df) df.loc[len(df.index)] = ['Amy', 89, 93] display(df)> Sortir:
Exemple 2 :
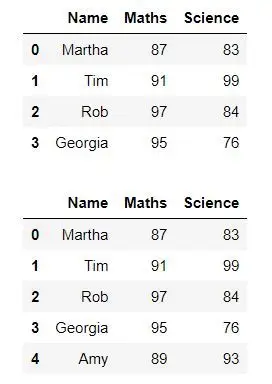
Nous pouvons également ajouter une nouvelle ligne en utilisant le DataFrame.append() fonction
Python from IPython.display import display, HTML import pandas as pd import numpy as np dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'], 'Maths':[87, 91, 97, 95], 'Science':[83, 99, 84, 76] } df = pd.DataFrame(dict) display(df) df2 = {'Name': 'Amy', 'Maths': 89, 'Science': 93} df = df._append(df2, ignore_index = True) display(df) # This code is modified by Susobhan Akhuli> Sortir:
Exemple 3 :
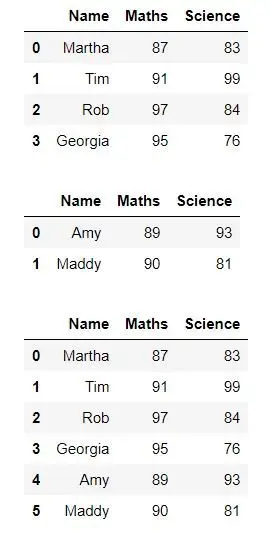
Nous pouvons également ajouter plusieurs lignes en utilisant le pandas.concat() en créant une nouvelle trame de données de toutes les lignes que nous devons ajouter, puis en ajoutant cette trame de données à la trame de données d'origine.
Python from IPython.display import display, HTML import pandas as pd import numpy as np dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'], 'Maths':[87, 91, 97, 95], 'Science':[83, 99, 84, 76] } df1 = pd.DataFrame(dict) display(df1) dict = {'Name':['Amy', 'Maddy'], 'Maths':[89, 90], 'Science':[93, 81] } df2 = pd.DataFrame(dict) display(df2) df3 = pd.concat([df1, df2], ignore_index = True) df3.reset_index() display(df3)> Sortir:
organisation et architecture informatique