Dans cet article, nous découvrirons ADT, mais avant de comprendre ce qu'est ADT, considérons les différents types de données intégrés qui nous sont fournis. Les types de données tels que int, float, double, long, etc. sont considérés comme des types de données intégrés et nous pouvons effectuer des opérations de base avec eux telles que l'addition, la soustraction, la division, la multiplication, etc. Il peut maintenant y avoir une situation où nous avons besoin d'opérations pour notre type de données défini par l'utilisateur qui doivent être définies. Ces opérations ne peuvent être définies qu’au fur et à mesure de nos besoins. Ainsi, afin de simplifier le processus de résolution des problèmes, nous pouvons créer des structures de données ainsi que leurs opérations, et ces structures de données qui ne sont pas intégrées sont connues sous le nom de type de données abstrait (ADT).
biais et variance
Le type de données abstrait (ADT) est un type (ou classe) pour les objets dont le comportement est défini par un ensemble de valeurs et un ensemble d'opérations. La définition de l'ADT mentionne uniquement quelles opérations doivent être effectuées mais pas comment ces opérations seront mises en œuvre. Il ne précise pas comment les données seront organisées en mémoire ni quels algorithmes seront utilisés pour mettre en œuvre les opérations. On l’appelle abstrait car il donne une vue indépendante de l’implémentation.
Le processus consistant à fournir uniquement l’essentiel et à masquer les détails est connu sous le nom d’abstraction.
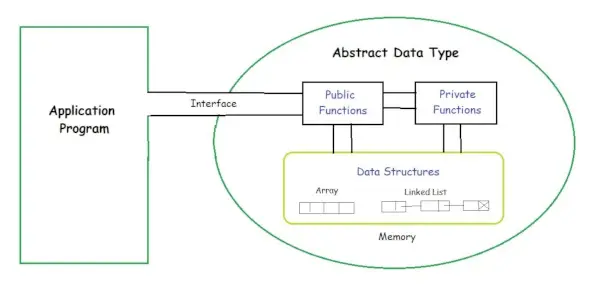
L'utilisateur de Ainsi, un utilisateur a seulement besoin de savoir ce qu’un type de données peut faire, mais pas comment il sera implémenté. Considérez ADT comme une boîte noire qui cache la structure interne et la conception du type de données. Nous allons maintenant définir trois ADT à savoir Liste ADT, File d'attente ADT.
1. Liste ADT
fonctionnalités de Java
Vies de liste
- Les données sont généralement stockées par séquence de touches dans une liste dont la structure principale est composée de compter , pointeurs et adresse de la fonction de comparaison nécessaire pour comparer les données de la liste.
- Le nœud de données contient le aiguille à une structure de données et à un pointeur autoréférentiel qui pointe vers le nœud suivant dans la liste.
- Le Liste des fonctions ADT est donné ci-dessous :
- get() – Renvoie un élément de la liste à une position donnée.
- insert() – Insère un élément à n’importe quelle position de la liste.
- remove() – Supprime la première occurrence de n'importe quel élément d'une liste non vide.
- removeAt() – Supprime l'élément à un emplacement spécifié d'une liste non vide.
- replace() – Remplacez un élément à n’importe quelle position par un autre élément.
- size() – Renvoie le nombre d'éléments dans la liste.
- isEmpty() – Renvoie vrai si la liste est vide, sinon renvoie faux.
- isFull() – Renvoie vrai si la liste est pleine, sinon renvoie faux.
2. Empiler ADT
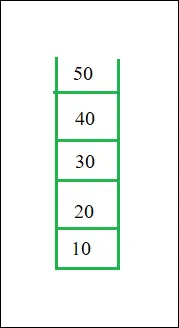
Vue de la pile
caractère en int java
- Dans l'implémentation Stack ADT, au lieu que les données soient stockées dans chaque nœud, le pointeur vers les données est stocké.
- Le programme alloue de la mémoire pour le données et adresse est passé à la pile ADT.
- Le nœud principal et les nœuds de données sont encapsulés dans l'ADT. La fonction appelante ne peut voir que le pointeur vers la pile.
- La structure de tête de pile contient également un pointeur vers haut et compter du nombre d'entrées actuellement dans la pile.
- push() – Insère un élément à une extrémité de la pile appelée top.
- pop() – Supprime et renvoie l'élément en haut de la pile, s'il n'est pas vide.
- peek() – Renvoie l'élément en haut de la pile sans le supprimer, si la pile n'est pas vide.
- size() – Renvoie le nombre d'éléments dans la pile.
- isEmpty() – Renvoie vrai si la pile est vide, sinon renvoie faux.
- isFull() – Renvoie vrai si la pile est pleine, sinon renvoie faux.
3. File d'attente ADT
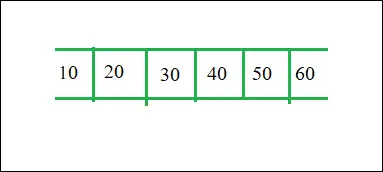
Vue de la file d'attente
- Le type de données abstrait de file d'attente (ADT) suit la conception de base du type de données abstrait de pile.
- Chaque nœud contient un pointeur vide vers le données et le pointeur de lien à l'élément suivant dans la file d'attente. La responsabilité du programme est d’allouer de la mémoire pour stocker les données.
- enqueue() – Insère un élément à la fin de la file d'attente.
- dequeue() – Supprime et renvoie le premier élément de la file d'attente, si la file d'attente n'est pas vide.
- peek() – Renvoie l'élément de la file d'attente sans le supprimer, si la file d'attente n'est pas vide.
- size() – Renvoie le nombre d'éléments dans la file d'attente.
- isEmpty() – Renvoie vrai si la file d'attente est vide, sinon renvoie faux.
- isFull() – Renvoie vrai si la file d'attente est pleine, sinon renvoie faux.
Caractéristiques de l'ADT :
Les types de données abstraits (ADT) sont un moyen d'encapsuler des données et des opérations sur ces données dans une seule unité. Certaines des fonctionnalités clés des ADT incluent :
- Abstraction: L'utilisateur n'a pas besoin de connaître la mise en œuvre de la structure des données, seuls les éléments essentiels sont fournis.
- Meilleure conceptualisation : ADT nous donne une meilleure conceptualisation du monde réel.
- Robuste: Le programme est robuste et a la capacité de détecter les erreurs.
- Encapsulation : Les ADT masquent les détails internes des données et fournissent une interface publique permettant aux utilisateurs d'interagir avec les données. Cela permet une maintenance et une modification plus faciles de la structure des données.
- Abstraction de données : Les ADT fournissent un niveau d'abstraction des détails de mise en œuvre des données. Les utilisateurs ont uniquement besoin de connaître les opérations qui peuvent être effectuées sur les données, et non la manière dont ces opérations sont mises en œuvre.
- Indépendance de la structure des données : Les ADT peuvent être implémentés en utilisant différentes structures de données, telles que des tableaux ou des listes chaînées, sans affecter la fonctionnalité de l'ADT.
- Masquage des informations : Les ADT peuvent protéger l’intégrité des données en autorisant l’accès uniquement aux utilisateurs et opérations autorisés. Cela permet d’éviter les erreurs et l’utilisation abusive des données.
- Modularité : Les ADT peuvent être combinés avec d’autres ADT pour former des structures de données plus grandes et plus complexes. Cela permet une plus grande flexibilité et modularité dans la programmation.
Dans l’ensemble, les ADT fournissent un outil puissant pour organiser et manipuler les données de manière structurée et efficace.
Les types de données abstraits (ADT) présentent plusieurs avantages et inconvénients qui doivent être pris en compte lors de la décision de les utiliser dans le développement de logiciels. Voici quelques-uns des principaux avantages et inconvénients de l’utilisation des ADT :
Avantages :
- Encapsulation : Les ADT offrent un moyen d'encapsuler les données et les opérations dans une seule unité, ce qui facilite la gestion et la modification de la structure des données.
- Abstraction : Les ADT permettent aux utilisateurs de travailler avec des structures de données sans avoir à connaître les détails de mise en œuvre, ce qui peut simplifier la programmation et réduire les erreurs.
- Indépendance de la structure des données : Les ADT peuvent être mis en œuvre à l'aide de différentes structures de données, ce qui peut faciliter leur adaptation à l'évolution des besoins et des exigences.
- Masquage d'informations : Les ADT peuvent protéger l’intégrité des données en contrôlant l’accès et en empêchant les modifications non autorisées.
- Modularité : Les ADT peuvent être combinés avec d'autres ADT pour former des structures de données plus complexes, ce qui peut augmenter la flexibilité et la modularité de la programmation.
Désavantages:
- Aérien : L'implémentation d'ADT peut ajouter une surcharge en termes de mémoire et de traitement, ce qui peut affecter les performances.
- Complexité : Les ADT peuvent être complexes à mettre en œuvre, en particulier pour les structures de données volumineuses et complexes.
- Apprentissage Courbe : L'utilisation des ADT nécessite une connaissance de leur mise en œuvre et de leur utilisation, ce qui peut prendre du temps et des efforts à apprendre.
- Flexibilité limitée : Certains ADT peuvent être limités dans leurs fonctionnalités ou ne pas convenir à tous les types de structures de données.
- Coût : La mise en œuvre des ADT peut nécessiter des ressources et des investissements supplémentaires, ce qui peut augmenter le coût de développement.
Dans l’ensemble, les avantages des ADT l’emportent souvent sur les inconvénients et ils sont largement utilisés dans le développement de logiciels pour gérer et manipuler les données de manière structurée et efficace. Cependant, il est important de prendre en compte les besoins et exigences spécifiques d'un projet au moment de décider d'utiliser ou non les ADT.
commandes ls Linux
De ces définitions, on voit bien que les définitions ne précisent pas comment ces ADT seront représentés et comment les opérations seront réalisées. Il peut y avoir différentes manières d'implémenter un ADT, par exemple, l'ADT List peut être implémenté à l'aide de tableaux, d'une liste simple chaînée ou d'une liste doublement chaînée. De même, stack ADT et Queue ADT peuvent être implémentés à l’aide de tableaux ou de listes chaînées.