Pour le fractionnement, nous avons ces fonctions :
np.hsplit :
Diviser le tableau le long de l’axe horizontal.
np.vsplit :
Diviser le tableau le long de l’axe vertical.
np.array_split :
Diviser le tableau le long de l'axe spécifié. Python
importnumpyasnpa=np.array([[1357911][24681012]])# horizontal splittingprint('Splitting along horizontal axis into 2 parts:n'np.hsplit(a2))# vertical splittingprint('nSplitting along vertical axis into 2 parts:n'np.vsplit(a2))
Le terme diffusion décrit comment NumPy traite les tableaux de formes différentes lors des opérations arithmétiques. Sous réserve de certaines contraintes, le plus petit réseau est « diffusé » à travers le plus grand réseau afin qu'ils aient des formes compatibles. La diffusion fournit un moyen de vectoriser les opérations sur les tableaux afin que le bouclage se produise en C au lieu de Python. Cela se fait sans faire de copies inutiles de données et conduit généralement à des implémentations efficaces d’algorithmes. Il existe également des cas où la diffusion est une mauvaise idée car elle conduit à une utilisation inefficace de la mémoire qui ralentit le calcul. Les opérations NumPy sont généralement effectuées élément par élément, ce qui nécessite que deux tableaux aient exactement la même forme. La règle de diffusion de Numpy assouplit cette contrainte lorsque les formes des tableaux répondent à certaines contraintes. La règle de diffusion : Afin de diffuser la taille des axes arrière des deux tableaux dans une opération, elle doit être soit de la même taille, soit l'un d'entre eux doit être un . Let us see some examples:
A(2-D array): 4 x 3 B(1-D array): 3 Result : 4 x 3
A(4-D array): 7 x 1 x 6 x 1 B(3-D array): 3 x 1 x 5 Result : 7 x 3 x 6 x 5
But this would be a mismatch:
A: 4 x 3 B: 4
The simplest broadcasting example occurs when an array and a scalar value are combined in an operation. Consider the example given below: Python
importnumpyasnpa=np.array([1.02.03.0])# Example 1b=2.0print(a*b)# Example 2c=[2.02.02.0]print(a*c)
Output:
[ 2. 4. 6.] [ 2. 4. 6.]
We can think of the scalar b being stretched during the arithmetic operation into an array with the same shape as a. The new elements in b as shown in above figure are simply copies of the original scalar. Although the stretching analogy is only conceptual. Numpy is smart enough to use the original scalar value without actually making copies so that broadcasting operations are as memory and computationally efficient as possible. Because Example 1 moves less memory (b is a scalar not an array) around during the multiplication it is about 10% faster than Example 2 using the standard numpy on Windows 2000 with one million element arrays! The figure below makes the concept more clear: In above example the scalar b is stretched to become an array of with the same shape as a so the shapes are compatible for element-by-element multiplication. Now let us see an example where both arrays get stretched. Python
Dans certains cas, la diffusion étend les deux tableaux pour former un tableau de sortie plus grand que l'un ou l'autre des tableaux initiaux.
Travailler avec datetime :
Numpy has core array data types which natively support datetime functionality. The data type is called datetime64 so named because datetime is already taken by the datetime library included in Python. Consider the example below for some examples: Python
importnumpyasnp# creating a datetoday=np.datetime64('2017-02-12')print('Date is:'today)print('Year is:'np.datetime64(today'Y'))# creating array of dates in a monthdates=np.arange('2017-02''2017-03'dtype='datetime64[D]')print('nDates of February 2017:n'dates)print('Today is February:'todayindates)# arithmetic operation on datesdur=np.datetime64('2017-05-22')-np.datetime64('2016-05-22')print('nNo. of days:'dur)print('No. of weeks:'np.timedelta64(dur'W'))# sorting datesa=np.array(['2017-02-12''2016-10-13''2019-05-22']dtype='datetime64')print('nDates in sorted order:'np.sort(a))
Output:
Date is: 2017-02-12 Year is: 2017 Dates of February 2017: ['2017-02-01' '2017-02-02' '2017-02-03' '2017-02-04' '2017-02-05' '2017-02-06' '2017-02-07' '2017-02-08' '2017-02-09' '2017-02-10' '2017-02-11' '2017-02-12' '2017-02-13' '2017-02-14' '2017-02-15' '2017-02-16' '2017-02-17' '2017-02-18' '2017-02-19' '2017-02-20' '2017-02-21' '2017-02-22' '2017-02-23' '2017-02-24' '2017-02-25' '2017-02-26' '2017-02-27' '2017-02-28'] Today is February: True No. of days: 365 days No. of weeks: 52 weeks Dates in sorted order: ['2016-10-13' '2017-02-12' '2019-05-22']
Algèbre linéaire dans NumPy :
Le module d'algèbre linéaire de NumPy propose diverses méthodes pour appliquer l'algèbre linéaire sur n'importe quel tableau numpy. Vous pouvez trouver :
trace déterminante du rang, etc. d'un tableau.
propres valeurs ou matrices
produits matriciels et vectoriels (produit point intérieur extérieur, etc.) exponentiation matricielle
résolvez des équations linéaires ou tensorielles et bien plus encore !
Consider the example below which explains how we can use NumPy to do some matrix operations. Python
importnumpyasnpA=np.array([[611][4-25][287]])print('Rank of A:'np.linalg.matrix_rank(A))print('nTrace of A:'np.trace(A))print('nDeterminant of A:'np.linalg.det(A))print('nInverse of A:n'np.linalg.inv(A))print('nMatrix A raised to power 3:n'np.linalg.matrix_power(A3))
Output:
Rank of A: 3 Trace of A: 11 Determinant of A: -306.0 Inverse of A: [[ 0.17647059 -0.00326797 -0.02287582] [ 0.05882353 -0.13071895 0.08496732] [-0.11764706 0.1503268 0.05228758]] Matrix A raised to power 3: [[336 162 228] [406 162 469] [698 702 905]]
Let us assume that we want to solve this linear equation set:
x + 2*y = 8 3*x + 4*y = 18
This problem can be solved using linalg.solve method as shown in example below: Python
importnumpyasnp# coefficientsa=np.array([[12][34]])# constantsb=np.array([818])print('Solution of linear equations:'np.linalg.solve(ab))
Output:
Solution of linear equations: [ 2. 3.]
Finally we see an example which shows how one can perform linear regression using least squares method. A linear regression line is of the form w1 x + w 2 = y et c'est la ligne qui minimise la somme des carrés de la distance de chaque point de données à la ligne. Ainsi, étant donné n paires de données (xi yi), les paramètres que nous recherchons sont w1 et w2 qui minimisent l'erreur : Let us have a look at the example below: Python
importnumpyasnpimportmatplotlib.pyplotasplt# x co-ordinatesx=np.arange(09)A=np.array([xnp.ones(9)])# linearly generated sequencey=[192020.521.522232325.524]# obtaining the parameters of regression linew=np.linalg.lstsq(A.Ty)[0]# plotting the lineline=w[0]*x+w[1]# regression lineplt.plot(xline'r-')plt.plot(xy'o')plt.show()
Output: Cela nous amène donc à la conclusion de cette série de tutoriels NumPy. NumPy est une bibliothèque à usage général largement utilisée qui est au cœur de nombreuses autres bibliothèques de calcul comme scipy scikit-learn tensorflow matplotlib opencv etc. Avoir une compréhension de base de NumPy aide à gérer efficacement d'autres bibliothèques de niveau supérieur ! Références :
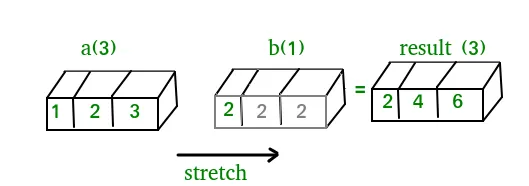 In above example the scalar b is stretched to become an array of with the same shape as a so the shapes are compatible for element-by-element multiplication. Now let us see an example where both arrays get stretched. Python
In above example the scalar b is stretched to become an array of with the same shape as a so the shapes are compatible for element-by-element multiplication. Now let us see an example where both arrays get stretched. Python  Dans certains cas, la diffusion étend les deux tableaux pour former un tableau de sortie plus grand que l'un ou l'autre des tableaux initiaux.
Dans certains cas, la diffusion étend les deux tableaux pour former un tableau de sortie plus grand que l'un ou l'autre des tableaux initiaux.  Let us have a look at the example below: Python
Let us have a look at the example below: Python  Cela nous amène donc à la conclusion de cette série de tutoriels NumPy. NumPy est une bibliothèque à usage général largement utilisée qui est au cœur de nombreuses autres bibliothèques de calcul comme scipy scikit-learn tensorflow matplotlib opencv etc. Avoir une compréhension de base de NumPy aide à gérer efficacement d'autres bibliothèques de niveau supérieur ! Références :
Cela nous amène donc à la conclusion de cette série de tutoriels NumPy. NumPy est une bibliothèque à usage général largement utilisée qui est au cœur de nombreuses autres bibliothèques de calcul comme scipy scikit-learn tensorflow matplotlib opencv etc. Avoir une compréhension de base de NumPy aide à gérer efficacement d'autres bibliothèques de niveau supérieur ! Références :